
사내에서 MongoDB를 잘 쓰기위한 스터디를 하게되어 이번 기회에 관련 자료를 정리하기로 했다. MongoDB가 왜 필요한지, 더 잘사용하기 위해서 무엇이 필요한지를 중심으로 처음 MongoDB를 사용할 때 도움이 될 만한 내용으로 정리했다.
NoSQL이란?
NoSQL은 Not Only SQL, SQL 뿐만 아니다라는 의미를 지니고있다. 즉, SQL을 사용하는 관계형 데이터베이스가 아닌 데이터베이스를 의미한다. 대표적인 관계형 데이터베이스로는 MySQL, Oracle, PostgreSQL이 있고, NoSQL 진영에는 이 포스트에서 다루는 MongoDB와 Redis, HBase 등이 있다.
NoSQL은 왜 탄생하게 된걸까? 사실 RDBMS만으로 충분하지 않을까? 하지만 RDBMS은 은총알이 아니었고 분명한 한계점이 있다. NoSQL은 다음과 같이 RDBMS에선 하기 힘든 일을 쉽게 지원한다.
- 수평 확장 가능한 분산 시스템
- Schema-less
- 완화된 ACID
RDBMS vs NoSQL
인터넷에 RDBMS와 NoSQL의 비교라고 검색하면 다음과 같은 표를 많이 볼 수 있다.
| RDBMS | NoSQL | |
|---|---|---|
| 적합한 사용례 | 데이터 정합성이 보장되어야 하는 은행 시스템 | 낮은 지연 시간, 가용성이 중요한 SNS 시스템 |
| 데이터 모델 | 정규화와 참조 무결성이 보장된 스키마 | 스키마가 없는 자유로운 데이터 모델 |
| 트랜젝션 | 강력한 ACID 지원 | 완화된 ACID(BASE) |
| 확장 | 하드웨어 강화(Scale up) | 수평 확장 가능한 분산 아키텍처(Scale out) |
| API | SQL 쿼리 | 객체 기반 API 제공 |
마치 RDBMS에 수평 확장이 불가능한 것 처럼 써놨지만 MySQL Replication이나 MySQL Cluster가 존재하여 수평 확장이 불가능한 것은 아니다. 그리고 NoSQL에서도 ACID가 불가능하지 않다. MongoDB의 경우 분산 트랜젝션까지도 지원하고 있다. 단, NoSQL 데이터베이스는 대게 분산 아키텍처를 염두하고 출시된 제품이 많아 더 편리하다는 장점이 있고 BASE 기반이기 때문에 완전한 ACID가 아니다. 점점 서로의 장점을 흡수하고 있기 때문에 위 표는 참고 정도로만 보면 될 것 같다.
그래서 MongoDB가 뭔데?
MongoDB는 앞서 설명한 것 처럼 NoSQL 데이터베이스고 다음 세 가지 특징을 가지고있다.
- Document
- BASE
- Open Source
데이터는 Document 기반으로 구성되어있고, ACID 대신 BASE를 택하여 성능과 가용성을 우선시한다. 그리고 오픈 소스라는 점 덕분에 무료로 이용이 가능하다.
여담으로 MongoDB는 분명 몇 년전까진 AGPL 라이센스였는데 어느 순간 SSPL(Server Side Public License)로 변경되었다. 아마 AWS(DocumentDB)나 Azure(CosmosDB)에서 별도 계약 없이 MongoDB를 이용해 돈을 벌었기 때문이 아닐까 싶다. 아무튼 아직 오픈 소스기는 하다1. MongoDB의 발전을 위한다면 클라우드 서비스 내 제품 대신 MongoDB Atlas를 이용하는 것이 좋을 것 같다. 비용도 AWS DocumentDB보단 저렴하게 시작할 수 있다.
Document
MongoDB는 Document 기반 데이터베이스다. Database > Collection > Document > Field 계층으로 이루어져 있으며 Document는 RDBMS의 Row에 해당한다. 계층은 RDBMS와 유사하다.
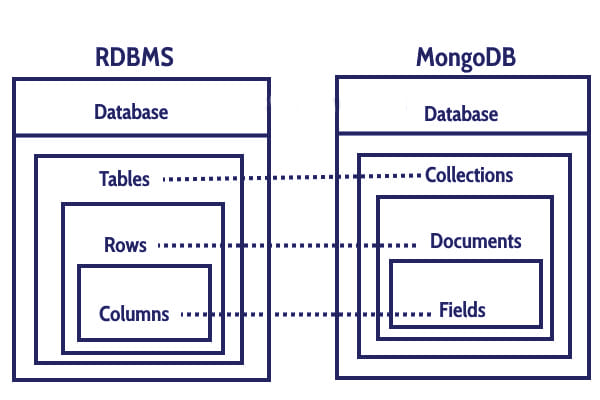
흥미로운 점은 Document 기반 데이터베이스은 RDBMS와 다르게 자유로이 데이터 구조를 잡을 수 있다는 점이다. MongoDB는 BSON으로 데이터가 쌓이기 때문에 Array 데이터나 Nested한 데이터를 쉽게 넣을 수 있다.

위 데이터 구조에서 ObjectId라는 생소한 타입을 볼 수 있다. ObjectId는 RDBMS의 Primary Key와 같이 고유한 키를 의미하는데 차이점은 Primary Key는 DBMS가 직접 부여한다면 ObjectId는 클라이언트에서 생성한다는 점이다. 이는 MongoDB 클러스터에서 Sharding된 데이터를 빠르게 가져오기 위함인데 Router(mongos)는 ObjectId를 보고 데이터가 존재하는 Shard에서 데이터를 요청할 수 있다. 의아하게도 MongoDB 서버에서 알아서 ObjectId를 부여해서 저장해도 될 것 같은데 딱히 지원해주지 않는다. 참고로 ObjectId를 넣지않고 저장한다면 데이터가 그대로 저장된다.
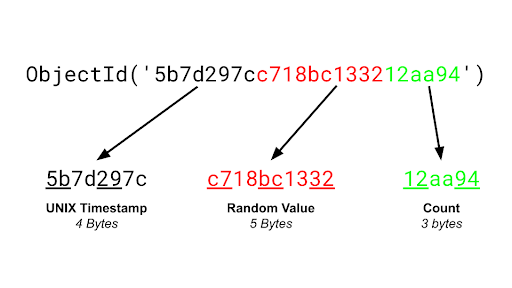
ObjectId는 세 영역으로 나눠져있다. 각각 첫 4 byte는 UNIX Timestamp 정보를 담고있고 다음 5 byte는 랜덤한 값으로 이루어져 있는데 3 byte와 2 byte로 나뉜다. 첫 3 byte는 클라이언트의 머신별로 고유한 키(mac 주소나 ip 주소)를 이용하여 랜덤 값을 만들어 사용한다. 다음 2 byte는 process id를 이용한다. 5 byte를 채운 후 마지막 2 byte는 Auto Increment되는 값으로 구성된다.
이쯤되면 ObjectId가 충돌날 가능성이 어느 정도일지 궁금할 수 있다. 충돌이 발생하려면 같은 시간, 기기에서 만들어낸 해시 값이 일치하고 우연히 같은 process id를 가지고 있으며 정말 우연히 increase된 count가 일치해야 한다. 확률은 계산해보지 않았지만 거의 충돌날 일은 없을 것 같다.2
다음으로 MongoDB 데이터 조작에 대해서 알아보자. MongoDB와 같은 NoSQL은 이름처럼 SQL을 사용하지 않고 별도로 제공하는 API를 통해 데이터를 건들 수 있다. MongoDB의 경우 자바스크립트 엔진 SpiderMonkey를 사용하여 API를 제공한다. 따라서 자바스크립트를 조금은 알아야한다.

데이터를 삽입하는 쿼��리를 보면 SQL과는 모습이 많이 다른 것을 알 수 있다. 마치 클래스에서 메서드를 통해 실행하는 모습인데, 이처럼 MongoDB는 객체 조작을 통해 데이터를 관리할 수 있다.
BASE
BASE는 ACID와 대립되는 개념으로 다음 세 가지로 이루어져있다.
- Basically Avaliable
- 기본적으로 언제든지 사용할 수 있다는 의미를 가지고 있다.
- 즉, 가용성이 필요하다는 뜻을 가진다.
- Soft state
- 외부의 개입이 없어도 정보가 변경될 수 있다는 의미를 가지고 있다.
- 네트워크 파티션 등 문제가 발생되어 일관성(Consistency)이 유지되지 않는 경우 일관성을 위해 데이터를 자동으로 수정한다.
- Eventually consistent
- 일시적으로 일관적이지 않은 상태가 되어도 일정 시간 후 일관적인 상태가 되어야한다는 의미를 가지고 있다.
- 장애 발생시 일관성을 유지하기 위한 이벤트를 발생시킨다.
이처럼 BASE는 ACID와는 다르게 일관성을 어느정도 포기하고 가용성을 우선시한다. 즉, 데이터가 조금 맞지 않더라도 일단 내려준다는 뜻이다.
참고로 굳이 왜 Basically Avaliable이나 Eventually consistent처럼 어렵게 표현했는지 의아했는데 Acid(산)과 대립되는 느낌을 주기 위해 억지로 Base(염기)로 맞췄다는 소리를 들었다. 물론 진짜인진 모르겠지만 꽤 재밌는 이야기라고 생각한다.
ACID?
마치 MongoDB는 전혀 ACID하지 않다는 식으로 글을 썼지만 사실 MongoDB는 트랜젝션을 제공한다. 아직 ACID하지 않을 때도 Single-Document Transaction을 제공하고 MongoDB 4.0부터는 Multi-Document Transaction을 제공함으로서 ACID를 충족했다. 이후 MongoDB 4.2에서 Shard Cluster Transacion을 제공하면서 분산 트랜젝션까지 가능해졌다.
MongoDB는 분산 시스템이 핵심이다
이번엔 MongoDB의 분산 시스템에 대해서 다뤄보자. MongoDB에서 분산 시스템은 기본으로 깔리고 들어가는만큼 반드시 알고 넘어가야하는 부분이다.

Thinking face가 생각한 것 처럼 웹 서비스가 발전하면서 데이터 무결성을 버리면서까지 더 많은 데이터, 빠른 성능, 수평 확장이 필요한 데이터베이스가 필요해졌다. 그런 요구 사항으로 인해 MongoDB가 탄생했다.
CAP 이론
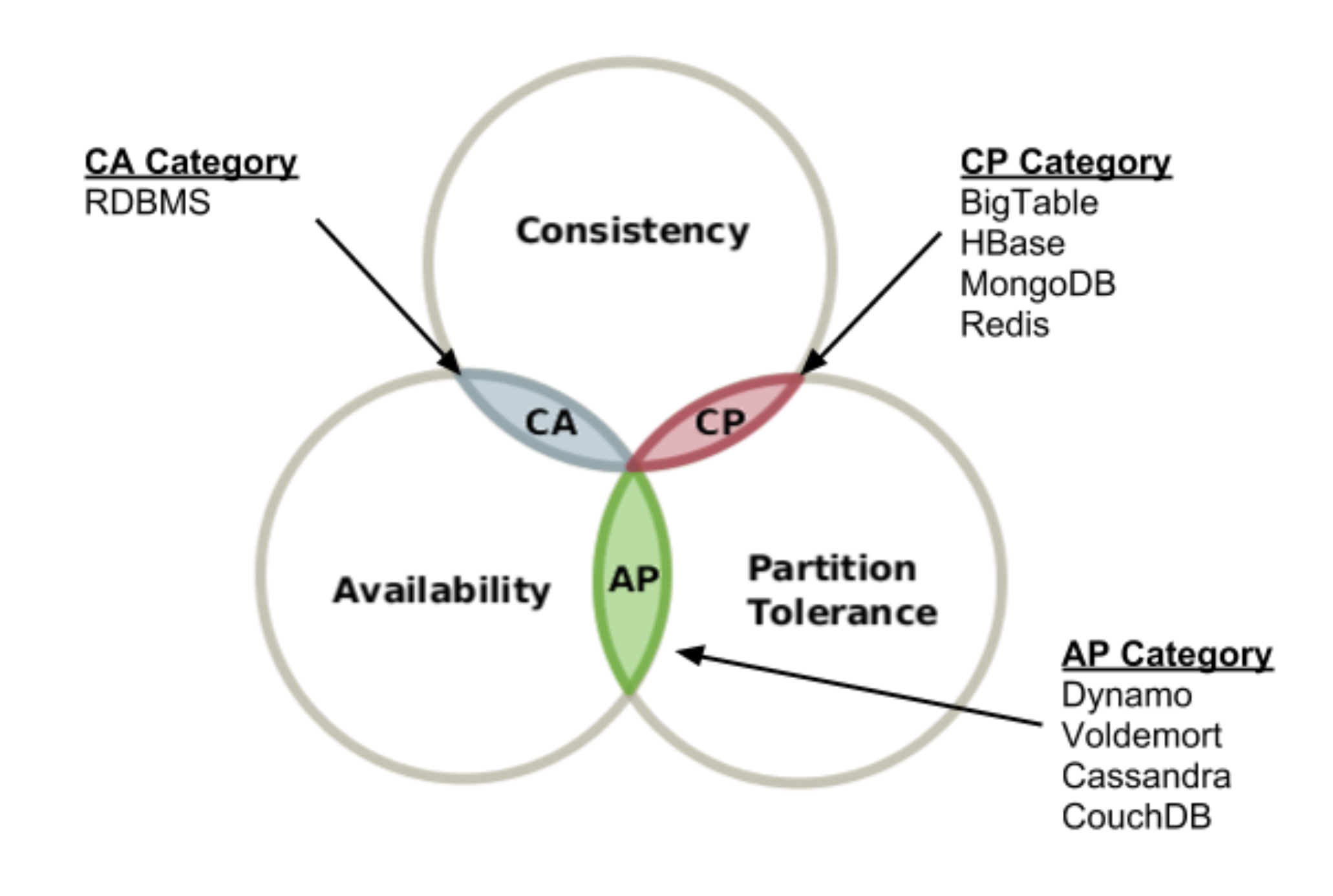
CAP 이론은 2000년에 에릭 브류어가 최초로 소개한 이론이며 어떤 분산 시스템이더라도 Consistency (일관성), Availability (가용성), Partition tolerance (분할 내성)를 모두 만족할 수 없다는 이론이다. 이 세 가지의 머리 글자를 따서 CAP 이론이라고 부른다.
Consistency는 모든 노드가 같은 시간에 같은 데이터를 볼 수 있다는 의미를 지닌다. 즉 데이터가 업데이트된 후 다른 노드에 동기화되어 모든 사용자가 최신 데이터를 본다면 일관성이 있는 시스템이다. 이를 위해선 동기화가 되는 동안 유저는 대기해야한다. 대기 시간이 길어질 경우 가용성이 떨어지는 시스템이다.
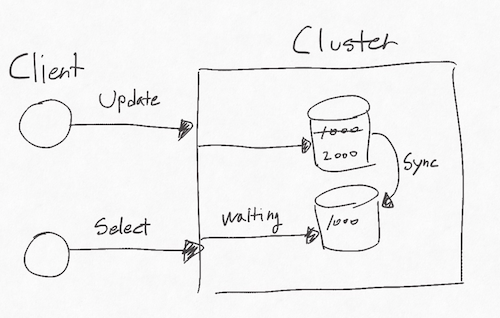
Availability는 모든 요청에 성공 혹은 실패 결과를 반환 할 수 있다는 의미를 지닌다. 하나의 노드가 망가져도 다른 노드를 통해 데이터를 제공할 수 있다면 가용성이 있는 시스템이다. 만약 다시 노드가 살아났을 때 다른 노드와 데이터가 다르다면 일관성이 떨어지는 시스템이다.
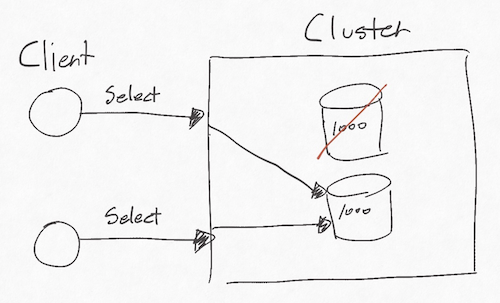
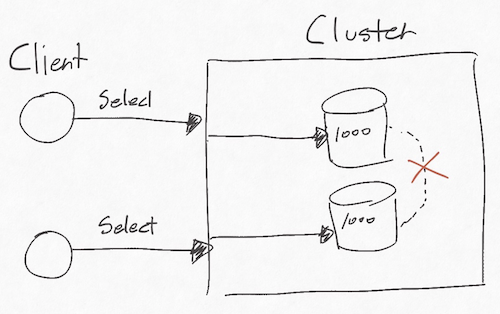
Partition tolerance는 통신에 실패해도 시스템이 계속 동작해야한다는 의미를 지닌다. 노드가 망가진 것이 아닌 노드를 연결시켜주는 네트워크가 고장나는 경우를 의미한다. 둘 사이 통신이 망가져서 동기화가 불가능해진다면 일관성이 떨어진다. 만약 통신이 복구되고 동기화되는 것을 기다린다면 가용성이 떨어진다. 결국 둘 다 만족할 수 없다.
CAP 이론의 한계
그렇다면 CAP 이론에 따라 MongoDB는 CP니까 일관성과 분할 내성을 지닌 데이터베이스일까? 어느정도 맞다고는 볼 수 있다. 그런데 여기서 하나 의심을 해보자. 과연 CA라는 시스템이 존재할 수 있을까?
CA는 네트워크 장애가 절대 발생하지 않아야 하기 때문에 사실상 불가능하다. 따라서 P는 무조건 발생한다고 본 후에 결정해야 한다.
그리고 CP, AP 둘 중 하나에 치우친 시스템은 좋지않다. 상황에 따라 유연하게 변하거나 개발자가 원하는 형태로 설정할 수 있는 방식이 가장 이상적이다. 그렇기에 대부분의 분산 시스템은 상황에 따라 일관성과 가용성의 우선 순위를 다르게 설정한다.
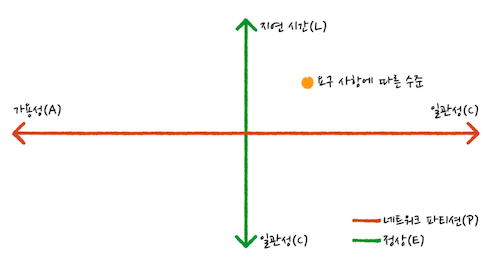
PACELC 이론
그래서 기본적으로 네트워크 파티션 상황은 반드시 발생한다 가정하고 그에 따른 선택을 정리한 이론이 PACELC 이론이다.
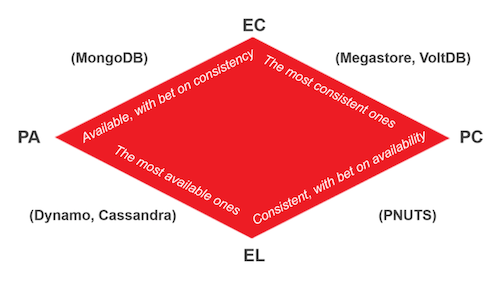
PACELC는 다음으로 이루어져 있다.
| 구분 | 구성 | 설명 |
|---|---|---|
| Partition | Availability | 가용성 |
| Consistency | 일관성 | |
| Else | Latency | 시간 지연 |
| Consistency | 일관성 |
여기서 Partition은 네트워크 파티션이 발생한 상태를 의미하고 Else는 정상 상태를 의미한다. 만약 PA / EL이라면 네트워크 파티션 상황일 때 가용성을 더 우선시하고 평상시에도 지연 시간을 더 신경쓰므로(일관성을 신경쓰느라 지연 시간이 늦어질수록 가용성이 떨어진다) 가용성을 우선시한다는 뜻이 된다. 정리하면 MongoDB는 PA / EC 시스템이므로 네트워크 파티션 상황일 때 가용성을 더 우선시하고 평상시엔 일관성을 우선시한다.
MongoDB Replica Set
MongoDB는 클러스터를 구성하기 위한 가장 간단한 방법으로 Replica Set을 이용할 수 있다. Replica Set은 다음 두 방법을 이용하여 구성할 수 있다.
- P-S-S
- P-S-A
Sharded 클러스터를 구성할 수도 있지만 이번 포스트에선 다루지 않는다.
P-S-S
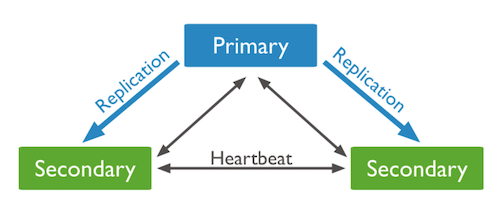
P-S-S 시스템은 하나의 Primary와 여러 개의 Secondary로 이루어진 Replica Set이다.
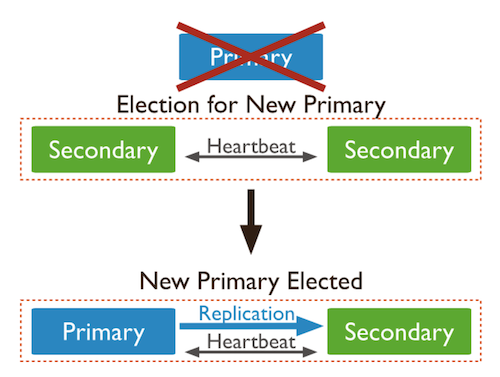
만약 Primary가 죽을 경우 투표를 통해 남은 Secondary 중 새로운 Primary를 선출한다. 여기서 만약 Secondary가 하나만 남았다면 새로운 Primary를 선출할 수 없어 서버 장애가 발생한다.
P-S-A
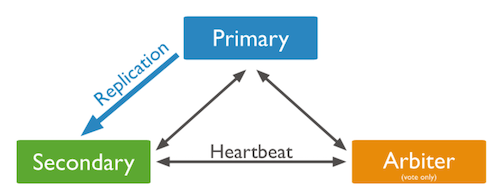
P-S-A 시스템은 하나의 Primary와 Arbiter 그리고 여러 개의 Secondary로 이루어진 Replica Set이다.
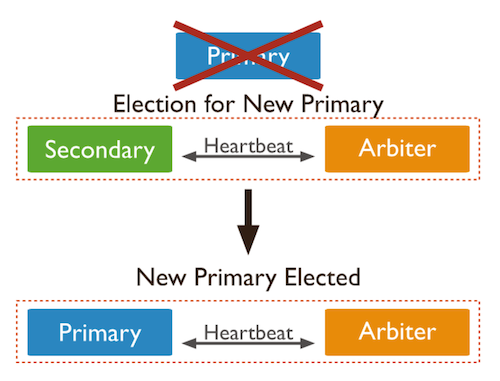
P-S-A 시스템에선 Primary가 죽은 경우 Arbiter가 Secondary와 함께 투표해서 Secondary 중 새로운 Primary를 선출한다. P-S-A 시스템에선 Secondary가 하나만 남았더라도 Arbiter가 남아있어서 남은 Secondary를 Primary로 선출 할 수 있어서 정상적으로 서비스가 동작한다.
MongoDB 패턴
MongoDB는 Document라는 방식을 사용하기 때문에 RDBMS와는 다른 방식으로 모델링을 해�야한다. 이를 위한 패턴을 정리해보자.
Model Tree Structure
같은 Collection에서 데이터가 서로를 참조하는 Tree 구조를 가지고 있을 때 사용할 수 있는 패턴은 다섯가지가 있다. 소개하는 모든 패턴은 아래 트리 구조를 참고하여 구성했다.
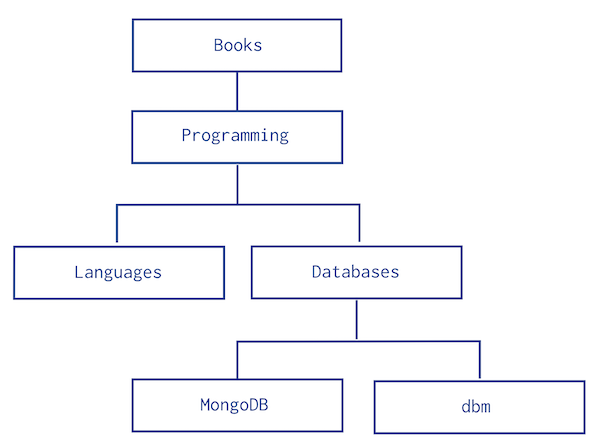
Parent References
Parent References는 다음과 같은 구조를 가진다.
[
{ _id: "MongoDB", parent: "Databases" },
{ _id: "dbm", parent: "Databases" },
{ _id: "Databases", parent: "Programming" },
{ _id: "Languages", parent: "Programming" },
{ _id: "Programming", parent: "Books" },
{ _id: "Books", parent: null }
]부모 Document를 바로 찾아야 하는 경우 적합하다. 만약 하위 트리를 모두 찾아야하는 경우엔 적합하지 않다.
Child References
Child References는 다음과 같은 구조를 가진다.
[
{ _id: "MongoDB", children: [] },
{ _id: "dbm", children: [] },
{ _id: "Databases", children: [ "MongoDB", "dbm" ] },
{ _id: "Languages", children: [] },
{ _id: "Programming", children: [ "Databases", "Languages" ] },
{ _id: "Books", children: [ "Programming" ] }
]자식 Document를 바로 찾아야하는 경우 적합하다. 부모 Document도 찾을 수 있지만 Parent References보다 탐색 성능이 느리다.
Array of Ancestors
Array of Ancestors는 다음과 같은 구조를 가진다.
[
{ _id: "MongoDB", ancestors: [ "Books", "Programming", "Databases" ], parent: "Databases" },
{ _id: "dbm", ancestors: [ "Books", "Programming", "Databases" ], parent: "Databases" },
{ _id: "Databases", ancestors: [ "Books", "Programming" ], parent: "Programming" },
{ _id: "Languages", ancestors: [ "Books", "Programming" ], parent: "Programming" },
{ _id: "Programming", ancestors: [ "Books" ], parent: "Books" },
{ _id: "Books", ancestors: [ ], parent: null }
]조상 Document를 바로 알 수 있어야하는 경우와 자식 Document를 모두 찾아야 하는 경우 적합하다. Breadcrumb 등에 쓸 수 있다. 만약 여러 부모 Document를 가진 경우 적합하지 않다.
Materialized Paths
Materialized Paths는 다음과 같은 구조를 가진다.
[
{ _id: "Books", path: null },
{ _id: "Programming", path: ",Books," },
{ _id: "Databases", path: ",Books,Programming," },
{ _id: "Languages", path: ",Books,Programming," },
{ _id: "MongoDB", path: ",Books,Programming,Databases," },
{ _id: "dbm", path: ",Books,Programming,Databases," }
]Array of Ancestors와 유사하다. Array 타입이 아닌 String 타입을 이용하는데 정규식을 이용하여 하위 항목을 찾을 수 있다. 이때 하위 트리를 찾는데에 Array of Ancestors보다 빠르다. 단, 공통 부모를 찾아야 하는 경우엔 더 느려질 수 있다.
Nested Sets
Nested Sets은 조금 특이한 구조를 가진다. 아래 그림의 번호를 참고하여 구조를 살펴보자.
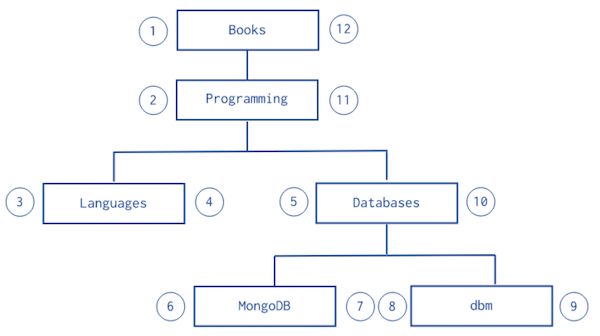
[
{ _id: "Books", parent: 0, left: 1, right: 12 },
{ _id: "Programming", parent: "Books", left: 2, right: 11 },
{ _id: "Languages", parent: "Programming", left: 3, right: 4 },
{ _id: "Databases", parent: "Programming", left: 5, right: 10 },
{ _id: "MongoDB", parent: "Databases", left: 6, right: 7 },
{ _id: "dbm", parent: "Databases", left: 8, right: 9 }
]하위 트리를 찾는데 가장 빠르고 효율적이다. 하지만 구조가 변경되는 경우 다시 데이터 번호를 매기는데 비용이 크기 때문에 데이터가 추가, 삭제, 변경되지 않는 정적인 구조에 적합하다.
Model Relationships
MongoDB도 RDBMS와 마찬가지로 1:1, 1:N, N:M 구조를 구성할 수 있다. 참조 방식만 제공하는 RDBMS와 다르게 MongoDB는 참조와 포함 두 가지를 제공한다. 참조는 Foreign Key처럼 키를 이용하여 참조하는 것이고 포함은 Document에 Object로 데이터를 포함하는 것을 의미한다.
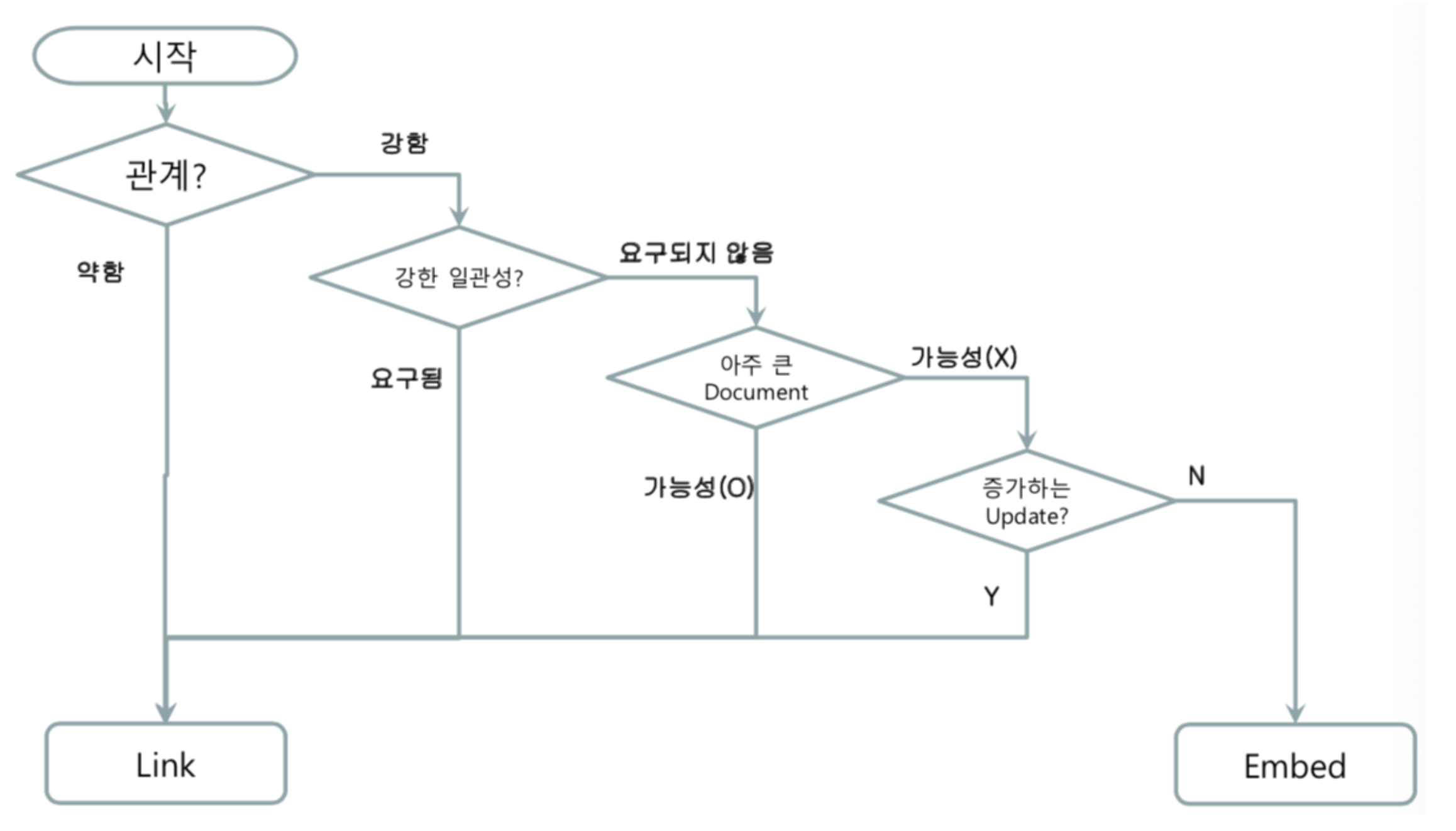
위 순서도는 자료 검색 중 발견했는데 참조와 포함 중 어떤 것을 선택 해야할지 고민할 때 크게 도움이 될 것 같아 저장했다. 순서도만보면 Embed는 잘 안쓰일 것 같지만 생각보다 정말 잘 쓰인다.
1:1을 구성한다면 가급적 Sub Document로 Embed하는 것이 좋다. 만약 Document의 크기가 너무 크다면 어쩔 수 없이 분리한다.
1:N은 위 순서도를 참고하여 구성한다. Link를 선택했을 때 자주 쓰이는 데이터가 있다면 후술할 Extended Reference 패턴이나 Subset 패턴을 이용한다. 1:N은 다음처럼 구성할 수 있다.
// 1이 N을 참조하는 방식
// Movie Collection
{
title: 'Star Wars',
reviews: [1, 2, 3]
}
// Review Collection
[
{
_id: 1,
comment: 'Good'
},
{
_id: 2,
comment: 'Good'
},
{
_id: 3,
comment: 'Good'
}
]// N이 1을 참조하는 방식
// Movie Collection
{
title: 'Star Wars',
}
// Review Collection
[
{
_id: 1,
title: 'Star wars',
comment: 'Good'
},
{
_id: 2,
title: 'Star wars',
comment: 'Good'
},
{
_id: 3,
title: 'Star wars',
comment: 'Good'
}
]MongoDB에서 N:M은 1:N에서 1이 N을 참조하는 방식으로 서로 참조하면 구성된다.
Modeling Pattern
MongoDB는 Subquery나 Join과 같은 기능을 제공해주지 않는다. Aggregation을 이용하면 엇비슷하게 사용할 수 있지만 여러 Collection을 참조하게 되면 성능이 크게 느려지기에 권장하지 않는다.
이 때 최대한 여러 Collection을 참조하는 것을 방지하고 데이터를 단순화하기 위해 모델링 패턴을 이용할 수 있다. 이 패턴은 공식 홈페이지에도 안내되어 있으며 이 포스트에선 자주 쓰이는 여섯 개 패턴을 소개한다.
Attribute
Attribute 패턴은 동일한 필드를 묶어서 인덱싱 수를 줄이는 패턴이다. 예를 들어 다음과 같이 데이터가 구성되어 있을 때는
{
title: "Star Wars",
director: "George Lucas",
...
release_US: ISODate("1977-05-20T01:00:00+01:00"),
release_France: ISODate("1977-10-19T01:00:00+01:00"),
release_Italy: ISODate("1977-10-20T01:00:00+01:00"),
release_UK: ISODate("1977-12-27T01:00:00+01:00"),
...
}각 국의 개봉 날짜로 검색이 필요한 경우 성능을 위해 인덱스를 걸어줘야한다.
{release_US: 1}
{release_France: 1}
{release_Italy: 1}
...하지만 이런 경우 인덱스가 너무 많아져서 관리가 복잡하고 용량이 증가하게된다. 이를 방지하기 위해 Attribute 패턴을 사용할 수 있다.
{
title: "Star Wars",
director: "George Lucas",
...
releases: [
{
location: "USA",
date: ISODate("1977-05-20T01:00:00+01:00")
},
{
location: "France",
date: ISODate("1977-10-19T01:00:00+01:00")
},
{
location: "Italy",
date: ISODate("1977-10-20T01:00:00+01:00")
},
{
location: "UK",
date: ISODate("1977-12-27T01:00:00+01:00")
},
...
],
...
}거창하게 소개했지만 단순히 하나의 필드에 묶어서 관리하는 것을 의미한다. 이 경우 인덱스를 두 개로 줄일 수 있다.
{ "releases.location": 1, "releases.date": 1}Extended Reference
Extended Reference 패턴은 서로 관계가 있는 Document에서 자주 사용되는 데이터를 저장해두는 패턴이다. MongoDB에선 성능을 위해 Join대신 쿼리를 두 번 날려 연관 데이터를 불러오는 방식을 많이 사용하는데 데이터가 많아질수록 불리하기 때문에 데이터가 많아지고 참조 자주 필요할 수록 Extended Reference 패턴을 사용해야한다.

위 Collection을 살펴보자. 주문을 하면 Order Collection에 데이터가 쌓이고 어떤 고객이 주문했는지 customor_id 필드에 기록된다. 아무런 문제가 없어 보이지만 만약 주문 내역을 사용자에게 보여줄 때 고객 정보도 보여줘야 한다면 Join이 필요해진다. 앞서 말했던 것 처럼 MongoDB에서 Join의 성능은 열악하기 때문에 곤란한 상황이 되어버린다. 이 때 사용할 수 있는 것이 Extended Reference 패턴이다.

Extended Reference 패턴은 위 그림처럼 필요한 데이터를 연관된 Collection에서 일부분 Document에 저장하는 것을 의미한다. 사실 RDBMS에서도 성능과 편의성을 위해 자주 사용하는 방법이다. 하지만 MongoDB는 어쩔 수 없이 꼭 써야하는 경우가 꽤 많다. 꼭 기억해두자.
Subset
Subset 패턴은 관계가 있는 Document 사이에 자주 사용되는 데이터를 부분적으로 Embed하는 패턴이다. 설명만 들으면 Extended Reference 패턴과 같아 보이지만 조금 다르다.

상품에 관한 Collection이 있고 해당 Collection에 리뷰를 Embed 형태로 저장한다고 가정해보자. 이 때 리뷰는 엄청 많아질 수 있기 때문에 별도 Collection으로 분리 해야한다. 분리하게 될 경우 두 번 쿼리를 날려야한다. 만약 빠르게 최신 5개 리뷰만 보여주고 싶다면 어떻게 해야할까?

답은 간단하다. 최신 5개 리뷰만 상품 Document에 저장해두면 된다. 이렇게 하면 빠르게 사용자에게 데이터를 전달 할 수 있다. 사용자에겐 더 보기 메뉴를 누를 수 있도록 UI를 제공 하면된다. MongoDB를 주력으로 이용한다면 Subset 패턴은 정말 많이 쓰이는 패턴이다. 꼭 기억해두자.
참고로 만약 데이터 수정이 발생한다면 양쪽을 모두 수정해야한다.
Computed
Computed 패턴은 미리 통계 수치를 데이터 삽입할 때 계산하는 패턴이다. 이 패턴도 RDBMS에서도 자주 쓰이는 패턴이다.
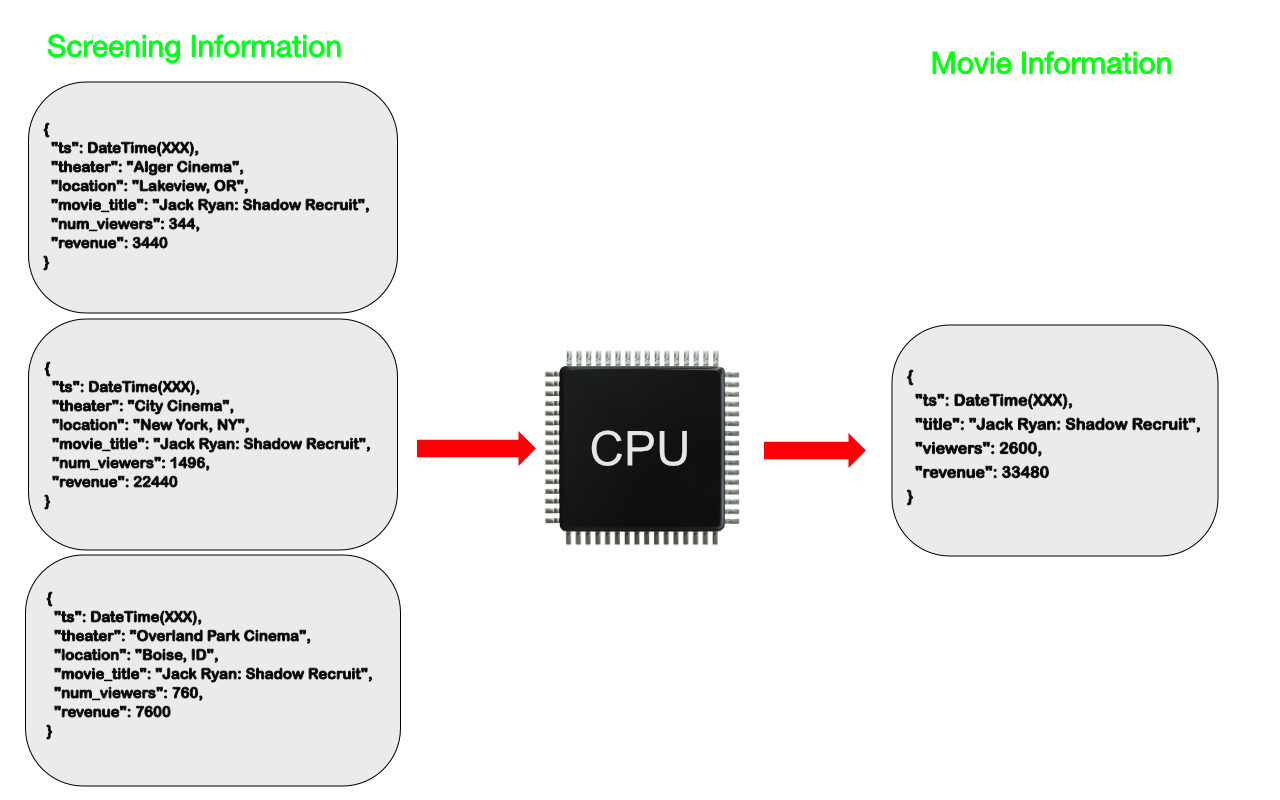
위 그림처럼 관객 수 합계가 필요하다면 read할 때 집계 함수를 사용할 수도 있지만 별도 필드에 미리 저장해두는 방법도 있다. 집계 합수는 데이터가 많을 수록 성능이 느리기 때문에 조금 오차가 발생해도 괜찮다면 Computed 패턴을 쓰는 것이 좋다.
Bucket
Bucket 패턴은 하나의 필드를 기준으로 Document를 묶는 패턴이다. 실시간으로 데이터가 들어오는 시계열 데이터에 적합하다.
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
}
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
}
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:02:00.000Z"),
temperature: 41
}위와 같은 형태로 로그성 데이터를 수집할 때 Computed 패턴을 사용하려면 별도 Collection에 데이터를 만들어서 저장해야한다. 하지만 Bucket 패턴을 이용하면 쉽게 해결할 수 있다.
{
sensor_id: 12345,
start_date: ISODate("2019-01-31T10:00:00.000Z"),
end_date: ISODate("2019-01-31T10:59:59.000Z"),
measurements: [
{
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
},
{
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
},
...
{
timestamp: ISODate("2019-01-31T10:42:00.000Z"),
temperature: 42
}
],
transaction_count: 42,
sum_temperature: 2413
} 위 구조를 보면 sensor_id를 기준으로 하나의 Document로 묶은 모습이다. 이때 transaction_count와 sum_temperature 필드처럼 집계를 위한 필드도 구성할 수 있다. 이 경우 필드 추가, 삭제에도 용이하고 인덱스 크기도 절약이 가능하다. 단, 조심해야할 점으로 BSON 크기 제한을 벗어나지 않도록 조심해야하는데 위 구조처럼 start_date, end_date를 이용하여 기준점을 가지고 묶는 것이 좋다.
Schema Versioning
Schema Versioning 패턴은 Document에 버전 정보를 기록하는 패턴이다. 서비스를 운영하다보면 스키마가 변경될 가능성이 높다. 이 때 Schema Versioning 패턴을 사용하면 기존 데이터를 급하게 마이그레이션하지 않아도 괜찮다.
{
"_id": "<ObjectId>",
"name": "Darth Vader",
"home": "503-555-0100",
"work": "503-555-0110",
"mobile": "503-555-0120"
}위 데이터의 필드를 변경해야한다고 가정해보자. 만약 데이터가 10억개가 넘는다면 마이그레이션을 하는 것도 꽤 큰 작업이된다. 이런 경우 Schema Versioning 패턴을 이용하면 다음과 같이 구성할 수 있다.
{
"_id": "<ObjectId>",
"schema_version": "2",
"name": "Anakin Skywalker (Retired)",
"contact_method": [
{ "work": "503-555-0210" },
{ "mobile": "503-555-0220" },
{ "twitter": "@anakinskywalker" },
{ "skype": "AlwaysWithYou" }
]
}schema_version 필드를 둬서 버전을 2로 설정했다. 이후 애플리케이션에서 find 할 때 schema_version 조건을 넣는다면 충돌없이 작업이 가능하다. 우선 이렇게 해결한 후 천천히 마이그레이션을 할 수 있다.
마치며
MongoDB와 RDBMS는 적합한 사용처가 다르다. 내 개인적인 생각으론 MongoDB를 비롯한 NoSQL은 최대한 단순하게 사용하는 것이 옳은 방향이라고 생각한다. NoSQL은 최대한 단순하면서 많은 데이터, RDBMS는 복잡하면서 무결성이 중요한 데이터에 적합하다고 생각한다. 물론 데이터를 단순화하는 것도 쉬운 일은 아니기 때문에 만약 당신이 MongoDB를 사용할 계획이 있다면 꼭 위 모델링 패턴을 참고하여 데이터 구조를 잡는 것을 추천한다.







