
저는 패러다임에 대한 이야기를 좋아합니다. 같은 문제를 두고 여러 사상을 통한 해결 방법을 비교하고, 그 중에서 가장 적합한 방법을 찾아내는 것이 재미있기 때문입니다. 그런 관점에서 데이터 지향 프로그래밍이라는 책이 출판됐을 때 굉장히 흥미로웠습니다.
데이터와 동작의 분리
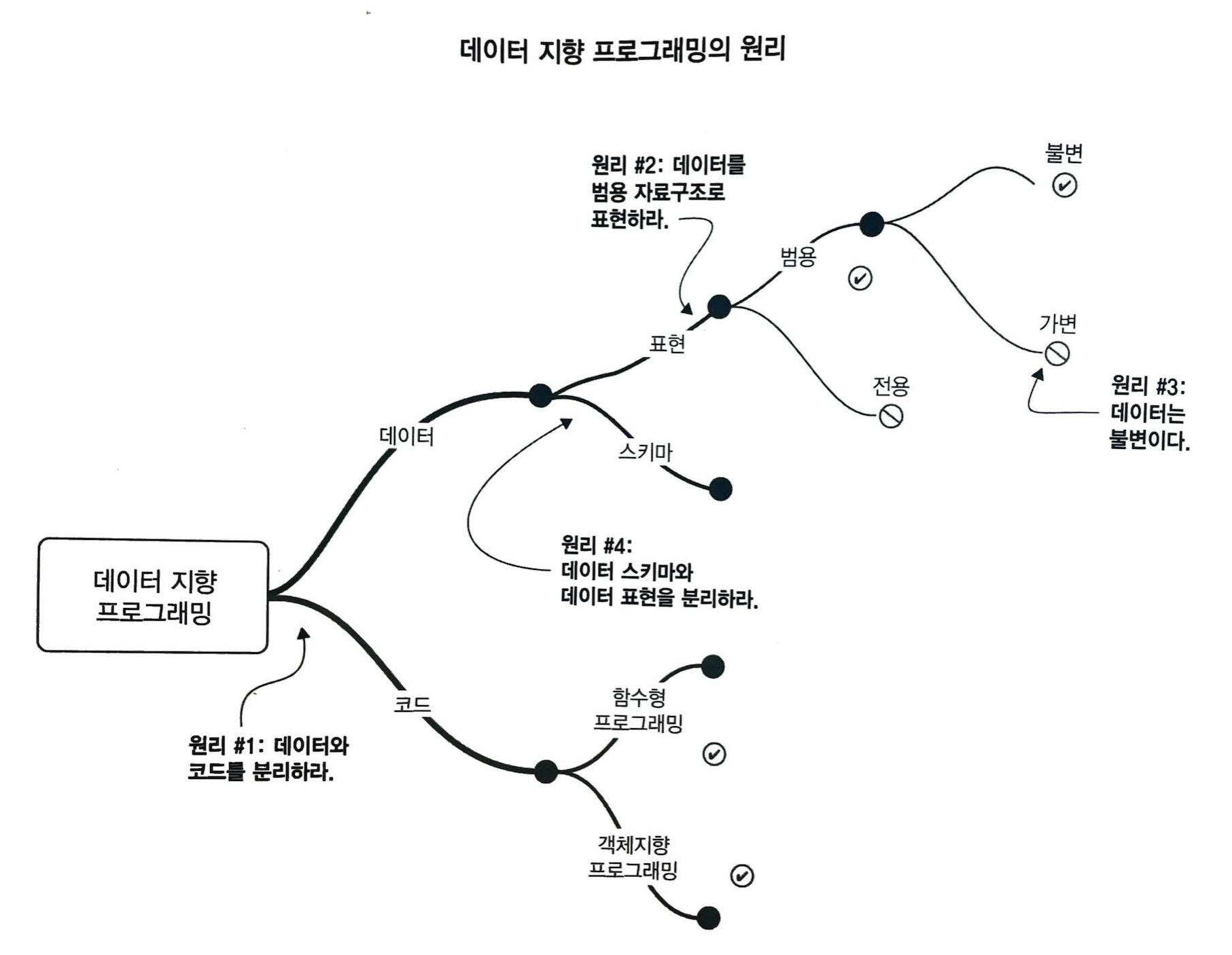
기본적으로 데이터 지향 프로그래밍은 데이터와 동작을 분리하는 것부터 시작합니다. 참고로 책에서는 동작이 아닌 코드라고 표현했지만 조금 혼란이 있을 수 있으니 저는 로직이라 표현하겠습니다.
객체 지향 프로그래밍에서는 데이터와 동작을 하나의 객체로 묶어서 관리합니다. 이는 데이터와 동작이 서로 의존하고 있기 때문입니다. 하지만 데이터 지향 프로그래밍에서는 데이터와 동작을 분리하여 데이터를 중심으로 프로그래밍 합니다. 데이터와 동작을 분리함으로서 설계 관점도 달라지게 됩니다. 객체 지향 프로그래밍에서는 객체의 책임과 역할을 중심으로 설계하지만 데이터 지향 프로그래밍에서는 데이터의 구조와 흐름을 중심으로 설계합니다.
이와 같은 방식은 과거 프로시저적 프로그래밍1과 유사하다는 생각이 들었습니다. 보통 서버 웹 애플리케이션을 작성할 때 풍부한 도메인 모델을 만들어 객체지향적으로 설계하고자 하지만 요청과 반환이라는 웹 서버의 특징과 단순성을 고려하여 프로시저적 프로그래밍으로 작성되는 경우가 많습니다. 이를 생각하면 데이터 지향 프로그래밍은 웹 서버 애플리케이션을 작성할 때 유용할 것 같습니다.
범용 자료구조 사용
이 책의 저자는 데이터 지향 프로그래밍을 할 때 Map과 같은 범용 자료구조 사용을 권장합니다. 이 말은 서버에서 데이터 응답을 위한 객체2를 만드는 대신 Map에 담으라는 뜻 입니다. 예를 들어 자바로 코드를 작성한다면 다음과 같습니다.
public Map<String, Object> getPerson() {
Map<String, Object> person = new HashMap<>();
person.put("name", "Sunhyoup Lee");
person.put("email", "kciter@naver.com");
person.put("role", "developer");
return person;
}정적 타입 언어를 사용하는 개발자라면 대부분 놀랄만한 코드입니다. 아니 타입이 없다면 그러면 뭘 믿고 코딩해야 하는지 모르겠습니다. 하지만 이 책에서는 이렇게 하는 것이 더 좋다고 주장합니다. 이유는 유연성(Flexibility)과 일반성(Genericity) 때문입니다. 우리가 우려했던 것처럼 안정성(Safety)은 떨어진다고3 말합니다. 이렇게 코드를 작성하면 수정에 유연하고, 데이터를 조작하는 것이 더 편리해진다고 합니다. 여기서 데이터 조작을 할 때는 map, filter, reduce와 같은 함수형 프로그래밍의 기법을 사용합니다.
안정성은 어떻게 보장할까요? 이 책에서는 검증 함수를 사용하는 것을 권장합니다. 다음은 검증 함수를 사용한 예시입니다.
public boolean isValidPerson(Map<String, Object> person) {
return person.containsKey("name") && person.containsKey("age") && person.containsKey("email");
}
public boolean isDeveloper(Map<String, Object> person) {
return person.get("role").equals("developer");
}실제로 로직을 구현할 때는 다음과 같이 사용합니다.
Map<String, Object> person = getPerson(); // 실제로는 DB에서 데이터를 가져올 것
if (isValidPerson(person) && isDeveloper(person)) {
// do something
}이를 통해 어느정도 안정성을 챙기고 데이터와 로직을 완전히 분리함으로서 유연성을 높일 수 있다고 합니다.
데이터와 로직을 분리하는 것으로 데이터에 좀 더 집중하고 유연성을 높이는 것은 이해했습니다. 그렇지만 굳이 Map과 같은 범용 자료구조를 이용하는 것이 맞을까요? 저는 이 부분에선 큰 의문을 느꼈습니다. Data Oriented Programming in Java라는 글에선 Map 대신 record 문법을 사용하고 있습니다. 저 또한 이 의견에 공감합니다. Map은 범용 자료구조기 때문에 어떤 데이터든 담을 수 있습니다. 하지만 이는 데이터의 구조를 알 수 없기 때문에 가독성 측면에서 많은 문제가 있다고 생각합니다. 또한, 책에서 제시한 검증 함수를 이용하는 것은 실수의 위험이 큽니다. 컴파일러에게 맡길 수 있는 방법이 있다면 이를 사용하는 것이 더 좋다고 생각합니다.
마치며
통칭해서 서비스라 부르는 소프트웨어에서 가장 중요하게 여겨지는 것은 결국 데이터입니다. 원천 데이터를 이용하여 사용자에게 가치를 제공하고 쌓인 데이터를 통해 새로운 비즈니스 기회를 발굴할 수도 있기 때문입니다. 그래서 이 책에서 말하는 데이터 지향이라는 것이 어떤 의미인지 이해는 갑니다. 어쩌면 개발자는 비즈니스의 근간이 되는 데이터를 등한시 했을 지도 모릅니다. 객체지향적인 개발을 한다고 하여 많은 객체를 만들고 함수형적인 개발을 한다고하여 순수하고 함수 조합을 중요시하는 것이 데이터를 중요시하는 것은 아니기 때문입니다. 오히려 비즈니스가 아닌 다른 가치에 매몰되어 간단하게 해결할 수 있는 문제를 복잡하게 만들기도 합니다. 그래서 원 데이터를 어떻게 취급하고, 어떻게 가공하여 사용자에게 제공할지에 대한 고민이 결국 비즈니스 로직의 핵심이라는 것을 깨달으면 데이터 지향 프로그래밍이라는 개념이 등장한 것도 자연스러운 일이라고 생각합니다.
당연하겠지만 이책에서 소개하는 데이터 지향 프로그래밍이 모든 문제에 대한 해결책은 아닙니다. 객체의 책임과 역할을 부여하고 그에 맞는 클래스를 만드는 것, 순수한 함수를 만들고 조합하는 것 등은 더욱 안전하고 유지보수하기 좋은 소프트웨어를 만드는 데에 필요합니다. 중요한 것은 더 잘만들기 위한 방법을 찾는 것이라고 생각합니다. 그리고 그 방법을 찾기 위해 다양한 패러다임을 접하고, 적용해보는 것이 중요하다고 생각합니다.








