
자료구조란 전기 신호의 나열로 이루어진 컴퓨터 세계의 데이터를 다차원으로 표현하는 것이라 볼 수 있다. 우리는 보통 전산화를 할 때 현상을 표현하기 위한 데이터 구조를 정의하고 이를 이용해 알고리즘을 구현한다.
그렇지만 우리가 일반적으로 학생 때 배우는 자료구조는 절차적으로 설계된 구조들이 대부분이다. 이러한 자료구조는 상태가 존재하지않는 순수한 함수형 언어에서는 사용할 수 없기 때문에 기존에 알고있던 지식을 활용할 수가 없다. 따라서 함수형 프로그래밍을 하고싶다면 그에 맞는 방식으로 데이터를 표현할 수 있어야 하고 이를 순수 함수형 자료구조라고 부른다.
사실 이 함수형 자료구조를 꼭 익혀야하는가라고 묻는다면 사실 그렇지는 않다. 요즘은 대부분의 언어들이 멀티 패러다임을 지향하고 있고 성능적인 이슈도 있기 때문에 순수 함수형 언어에서만 사용하는 자료구조들을 익힐 필요는 없다. 그렇지만 이런 일반적이지 않은 것을 공부하는 것은 개발자로서 큰 즐거움아닐까?
함수형 사고
함수형 프로그래밍은 많은 개발자들이 관심을 가지며 업무에 활용하고 싶어하는 패러다임이다. 필자도 강의를 할 때 관련하여 많은 질문을 받기도하고 함수형 프로그래밍을 사용하는 회사는 힙한 기술 스택을 가진 멋진 회사로 인용되기도 한다. 이쯤되면 개발자에게 일종의 로망으로 자리잡았다고 생각된다.
이 포스팅을 이해하기 위해서는 우선적으로 함수형 프로그래밍에 대한 이해가 필요하다. 이를 위해 우리는 프로그래밍 패러다임이 무엇인지, 함수형으로 사고하는 방법을 알아야 한다.
프로그래밍과 패러다임, 방법론
💡 이 부분에 대한 설명은 필자의 생각이 듬뿍 담겨있다. 대체로 프로그래밍 패러다임과 방법론은 동일시 되는 경우가 많지만 이 글에서는 분리하여 표현한다.
프로그래밍 패러다임은 프로그램의 구성 요소와 프로그래밍을 하는 방법에 관한 사고 방식이라 볼 수 있다. 이는 프로그래밍 언어의 문법과 여러 기술과는 별개로 개발을 바라보는 시각이다. 이 말이 이해하기 어려울 수 있다. 예를 들어, 객체지향 프로그래밍은 프로그램은 객체들의 유기적인 통신을 통해 이루어지기에 객체를 올바르게 만들어 서로 상호작용하도록 해야한다라고 바라본다고 할 수 있다. 반면, 이 글에서 언급되는 함수형 프로그래밍은 프로그램은 하나의 함수이며 복잡한 연산을 위해 여러 함수의 합성을 통해 프로그램을 만들 수 있도록 해야한다라고 바라본다고 할 수 있다.
즉, 패러다임은 프로그램을 바라보는 시각을 통해 프로그래밍을 하는 방법을 결정한다. 이는 추상적인 사고와도 연관이 있다. 같은 프로그램을 만들더라도 바라보는 시각에 따라 뽑아내는 요소가 다르기 때문이다. 예를 들어, 이 글을 읽는 독자 여러분이 객체지향 프로그래밍에 익숙하다면 어떠한 문제를 해결할 때 객체를 만들기 위해 클래스 설계부터 할 것이고 함수형 프로그래밍에 익숙하다면 어떠한 문제를 해결할 때 문제를 분해하고 함수 합성을 할 수 있도록 설계부터 할 것이다.
그렇다면 방법론은 무엇일까? 프로그래밍 패러다임이 프로그램의 구성 요소를 바라보는 것이라면 방법론은 그러한 시각에 따라 문제를 해결하는 방법이라 볼 수 있다.
예를 들어, 이전에 작성했던 글인 Railway-Oriented Programming은 함수형 프로그래밍을 기반으로 한 방법론이라고 볼 수 있다. 객체지향 프로그래밍도 마찬가지로 여러 방법론을 가진다. 객체를 만들어 내는 방법을 클래스로 할 것인가, 프로토타입으로 할 것인가로 나뉘기도 하며 Go 언어처럼 상속을 지원하지 않는 경우도 있다. 이처럼 프로그램의 구성 요소를 바라보는 시각은 같아도 해결하는 방법은 달라질 수 있다.
함수형 프로그래밍은 좋은가?
물론 함수형 프로그래밍 좋다. 교과서적으로 대답하자면 안전한 프로그램을 작성하고 재사용성이 높아지며 테스트하기 쉽고, 불변성을 지키기 때문에 예측하기 쉽다. 이는 유지보수가 중요한 소프트웨어에서 매우 중요하다 할 수 있다. 물론 이러한 것들은 전부 적합한 상황에서 잘 만들었을 때만 해당한다. 당연히 함수형 프로그래밍도 다른 패러다임과 마찬가지로 많은 장점과 더불어 많은 단점이 존재한다.
함수형 프로그래밍을 포함하여 유명인이 언급하거나 큰 기업에서 사용하는 특정 방법론은 흔히 완벽한 방법으로서 맹신되기도 하는데 이런 생각은 위험하다. 방법론의 사전적인 의미를 보면 철학이나 과학 연구에서 진리에 도달하기 위한 방법을 연구하는 이론이라 나와있다. 이 말은 추상적이니 구체적인 예시를 들어보자.
가령 필자가 급한 출장으로 인해 서울에서 부산으로 이동해야 한다면 어떤 방법을 선택할 수 있을까? 먼저 비행기를 타는 방법을 선택할 수 있다. 이는 비용이 많이 드는 대신 빠르게 이동할 수 있다는 장점이 있다. 혹은 버스를 타는 방법이 있다. 이는 비행기보다 오래 걸리지만 비용이 더 저렴하다는 장점이 있다. 이 두 가지를 비행기 방법론과 버스 방법론이라고 할 때 상황에 따라 방법론을 선택할 수 있다. 만약 필자가 최대한 빠른 시간 내에 부산에 가야한다면 비행기 방법론을 택할 것이고 금전이 부족한 상황에선 버스 방법론을 택할 것이다. 이처럼 상황에 맞게 방법론을 선택하는 것이 가장 최선이라 볼 수 있다.
프로그래밍 패러다임과 방법론도 마찬가지로 가령 성능이 정말 중요한 낮은 계층의 소프트웨어를 만든다면 최소한의 명령어와 메모리만을 이용하기 위해 꼭 필요한 코드만을 순차적으로 작성할 수도 있다. 그리고 조금 더 큰 범위에서 아키텍처를 바라볼 때 MSA처럼 역할에 따라 서버를 분리하고 서로 통신하게끔 만든다면 이를 함수로 바라보는 것보다는 객체로 바라보는 것이 더 적합할 것이다. 이처럼 패러다임과 방법론은 어디에도 적용될 수 있지만 그에 따른 부작용이 있을 수 있기에 상황에 맞게 선택하는 것이 중요하다는 점을 꼭 명심해야 한다.
함수형 자료구조 개론
여기서 함수형 프로그래밍에 대해 깊게 다루는 것은 이 글의 범위를 벗어나기에 생략한다. 함수형 자료구조는 우리가 지금까지 배웠던 자료구조와는 달리 불변성을 가진다. 이는 상태를 지니지 않기에 값을 변경하지 않는다는 것을 의미한다. 여기서는 정말로 함수만을 이용하여 자료구조를 구현한다. 이를 위해 기본적으로 함수가 일급 객체인 언어여야 한다.
또한, 함수형 프로그래밍을 위한 여러 기술 중 Recursive Data Type이 필요하다. 이는 Lisp, Haskell, Scala 등 함수형 프로그래밍 언어나 TypeScript 등의 언어에서 지원한다. 혹은 JavaScript 같이 Duck Typing을 지원하는 언어에서 가능하다. 이 글에서는 상대적으로 이해하기 쉽고 타입도 나타낼 수 있는 TypeScript를 기준으로 설명한다.
Recursive Data Type
함수형 자료구조를 본격적으로 들어가기 전에 앞서 필요하다 말한 기술인 Recursive Data Type에 대해 간단히 살펴보자. Recursive Data Type은 이름처럼 재귀적인 타입 선언이다. 이는 타입을 정의할 때 타입 자신을 참조하는 것을 의미한다. 이는 다음과 같이 표현할 수 있다.
type RecursiveType = (f: RecursiveType) => number;Recursive Data Type은 좀 더 유용한 사용 방법이 있지만 위 코드처럼 함수 타입으로 사용하는 것도 가능하다. 참고로 Recursive Data Type을 지원하지 않는 언어는 위와 같은 코드를 작성할 수 없다.
// Kotlin
typealias RecursiveType = (RecursiveType) -> Int // 컴파일 에러 발생다른 언어에서는 타입을 정의할 때 자기 자신에 대한 정의를 할 수 없는 경우가 있다. 반면 TypeScript는 가능하다. 이는 함수형 자료구조를 만들 때 유용하다.
함수로 구조를 어떻게 표현할까?
언뜻 함수로 구조를 나타낸다는 것이 이상하게 느껴질 수 있다. 하지만 잘 생각해보면 함수로도 충분히 데이터 구조를 나타낼 수 있다. 다음 코드를 살펴보자.
function Pair(left: number, right: number) {
// ...
}위 코드에서 매개 변수인 left와 right를 통해 Pair 함수가 두 개의 데이터를 받을 수 있다는 것을 알 수 있다. 그럼 위 함수를 조금 더 확장시켜보자.
function Pair(left: number, right: number) {
return function (f: (left: number, right: number) => number) {
return f(left, right);
};
}추가로 Pair 함수에서 다시 함수를 반환하도록 코드를 작성했다. 여기서 갑자기 머리가 아파올 수 있다. 천천히 코드를 뜯어보자. Pair 함수는 left와 right를 매개 변수로 받는다. 그리고 Pair 함수는 함수를 반환한다. 이 함수는 f라는 매개 변수를 받는다. 이 f는 left와 right를 매개 변수로 받아 number를 반환한다. 정리하여 순서대로 나타내면 다음과 같다.
- Pair가 숫자 두 개를 입력 받는다.
- Pair는 숫자 두 개를 입력 받아 숫자를 반환하는 함수를 반환한다. 이때, 숫자 두 개는 클로저(혹은 람다 캡처링)로 인해 메모리 상에 남아있다.
- 반환된 함수는 숫자 두 개를 입력 받아 적절한 처리 후 숫자를 반환한다.
설명보다 코드가 더 이해하기 쉬울 수 있다. 실제로 사용하는 코드를 살펴보자.
const pair = Pair(1, 2);
const result = pair((left, right) => left + right);
console.log(result); // 3첫 번째 줄 pair는 함수다. 이 함수는 다시 함수를 인자로 받을 수 있다. 그리고 pair 함수가 실행될 때 인자로 받은 함수를 실행시키며 값을 반환한다. 이때 중요한 것은 앞서 Pair 함수를 통해 받은 left와 right가 클로저로 인해 메모리 상에 남아있다는 것이다. 이를 통해 데이터를 담아두고 사용할 수 있다는 것을 알 수 있다. 데이터를 담아두고 사용할 수 있다면 구조체 혹은 클래스처럼 데이터를 담아두고 꺼내 쓸 수 있다고 볼 수 있다.
선형 자료구조 구현
앞서 함수로도 충분히 데이터를 담아두고 꺼낼 수 있다는 것을 알았다. 이번에는 이를 이용하여 선형 자료구조를 구현해보자. 먼저 대표적인 선형 자료구조인 단일 연결 리스트를 구현해볼 것이다.
일반적으로 TypeScript에서 단일 연결 리스트를 구현할 때는 다음과 같이 데이터 타입을 정의한다.
class Node {
constructor(public value: number, public next: Node | null) {
// ...
}
}
class LinkedList {
constructor(public head: Node | null) {
// ...
}
}위 코드는 Node와 LinkedList라는 두 개의 클래스를 정의한다. Node는 value와 next를 가지며 LinkedList는 head를 가진다. 이를 함수형 자료구조로 표현한다면 어떨까?
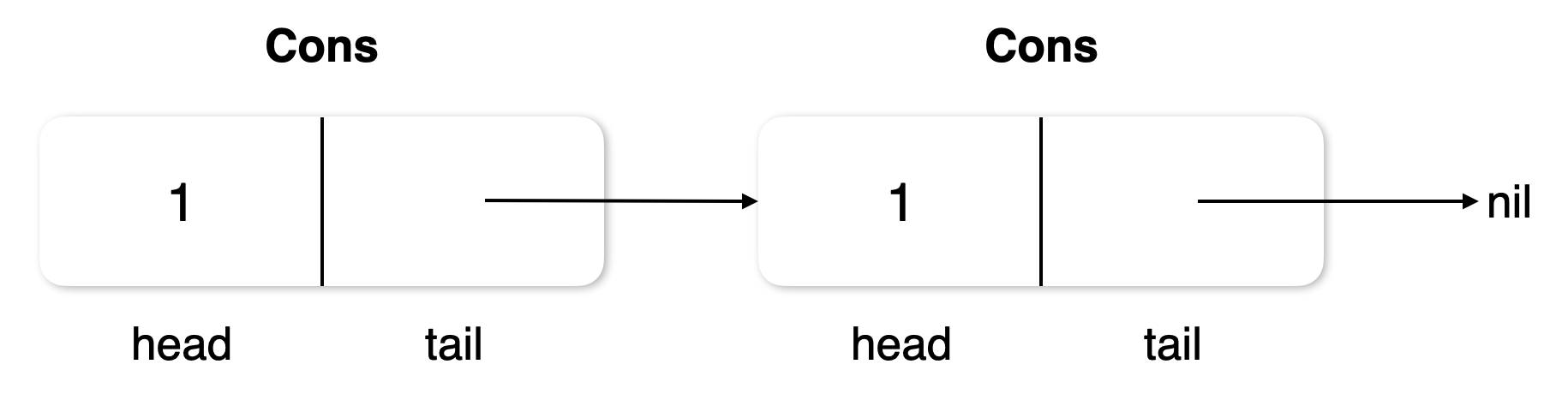
참고로 함수형 자료구조에선 요소를 Cons라고 표현하며 비어있는 값을 Nil이라 표현한다. 이는 Lisp에서 유래된 표현으로 Cons는 Construct(결합)를 줄여쓴 표현이다.
이어서 단일 연결 리스트를 더 이상 분해가 불가능할 때까지 분해한다고 생각해 보자. 그렇다면 head와 tail만 남은 Node 하나로 구성된 단일 연결 리스트가 남을 것이다. 이를 함수로 표현하고 tail은 다음 연결 리스트 혹은 null을 반환하도록 구현할 수 있다. 먼저 타입을 분해하여 정의할 필요가 있다. 필요한 타입은 다음과 같다.
- 단일 연결 리스트를 나타내는 타입
- 단일 연결 리스트의 요소를 표현하는 타입
- 단일 연결 리스트를 분해하는 타입
생각보다 정의할 타입이 많다. 코드로 한 번 살펴보자.
type ListNode = (head: number, tail: DestructureCons | null) => number | DestructureCons | null;
type DestructureCons = (destructureCons: ListNode) => ReturnType<ListNode>;
type LinkedList = (head: number, tail: DestructureCons | null) => DestructureCons;생각보다 타입 정의가 복잡하다. 여기서 앞서 설명한 Recursive Data Type이 사용된다. 직접 자기 자신을 참조하지는 않지만 상호 재귀로 서로를 참조하고 있다. 각 정의를 살펴보면 다음과 같다.
- 단일 연결 리스트를 나타내는 타입
- LinkedList
- 단일 연결 리스트의 요소를 표현하는 함수 타입
- ListNode
- 단일 연결 리스트를 분해하는 타입
- DestructureCons
타입 중 LinkedList와 DestructureCons는 합치면 앞서 살펴본 Pair와 유사하므로 어렵지 않을 것이다. ListNode는 head와 tail을 인자로 받아 head를 반환하거나 다음 요소를 반환하는 타입이다. 위 타입을 이용하여 단일 연결 리스트를 구성하는 Cons 함수를 만들어보자.
const Cons: LinkedList = (head, tail) => (destructureCons) => destructureCons(head, tail);앞서 구현한 Pair 함수와 똑같다. 실제로 사용할 때는 다음과 같다.
const list = Cons(1, Cons(2, Cons(3, null)));
const head = list((head, tail) => {
return head;
});
console.log(head); // 1만약 두 번째 요소의 값을 받아오고 싶다면 다음과 같이 작성할 수 있다.
const list = Cons(1, Cons(2, Cons(3, null)));
const second = list((head, tail) => {
if (tail === null) return null;
return tail((head, tail) => {
return head;
});
});
console.log(second); // 2솔직히 매우 불편하다. 이를 해결하기 위해 유용한 함수를 만들 수 있다.
const list = Cons(1, Cons(2, Cons(3, null)));
const get = (index: number, list: DestructureCons | null) =>
list === null ? new Error('Out of bound') :
list((head, tail) =>
index === 0 ? head : get(index - 1, tail));
console.log(get(2, list)); // 3
console.log(get(3, list)); // Error: Out of bound함수 내용이 조금 복잡할 수 있다. get은 인덱스를 받아 해당 인덱스의 값을 반환한다. 만약 인덱스가 리스트의 길이보다 크다면 에러를 반환한다. 이를 구현하기 위해 get 함수는 재귀적으로 호출한다. 이를 통해 인덱스가 0이 될 때까지 리스트를 분해하고 0이 되면 위치에 해당하는 요소를 반환한다. 추가로 함수를 더 만들어보자. 함수에 대한 설명은 주석을 참고하면 된다.
const list = Cons(1, Cons(2, Cons(3, null)));
// 리스트의 가장 첫 번째 요소의 값을 반환하는 함수
const head = (list: DestructureCons | null) => {
if (list === null) throw new Error('Empty list');
return list((head, _) => head);
}
// 요소 중 index에 해당하는 값을 반환하는 함수
const get = (index: number, list: DestructureCons | null) => {
if (list === null) throw new Error('Out of bound');
return list((head, tail) =>
index === 0 ? head : get(index - 1, tail));
}
// 리스트 마지막에 값을 추가하는 함수
const append = (value: number, list: DestructureCons | null) =>
list === null ?
Cons(value, null) :
list((head, tail) =>
tail === null ? Cons(head, Cons(value, null)) : Cons(head, append(value, tail)));
// 리스트 앞쪽에 값을 추가하는 함수
const prepend = (value: number, list: DestructureCons | null) => Cons(value, list);
// 리스트 첫 번째 요소를 제거하는 함수
const shift = (list: DestructureCons | null): DestructureCons => {
if (list === null) throw new Error('Empty list');
return list((_, tail) => tail) as DestructureCons;
}
// 리스트를 뒤집는 함수
const reverse = (list: DestructureCons) =>
list((head, tail) =>
tail === null ? Cons(head, null) : append(head, reverse(tail)));
// 리스트 요소의 값을 업데이트하는 함수
const update = (index: number, value: number, list: DestructureCons | null) => {
if (list === null) throw new Error('Out of bound');
return list((head, tail) =>
index === 0 ? Cons(value, tail) : Cons(head, update(index - 1, value, tail)));
}
// 리스트를 배열로 변환하는 함수
const toArray = (list: DestructureCons | null) =>
list === null ? [] : list((head, tail) => [head].concat(toArray(tail)));이제 이를 이용하여 리스트를 조작해보자.
const list = Cons(1, Cons(2, Cons(3, null)));
console.log(toArray(update(0, 10, shift(append(4, list))))); // [10, 3, 4]위 코드처럼 함수 합성을 통해 리스트를 조작할 수 있다. 결과적으로 불변성을 지니고 함수만을 이용하여 단일 연결 리스트를 구현하는데 성공했다! 이제 이를 응용하면 스택, 큐, 트리 등 다양한 자료구조를 구현하는 것도 가능하다.
커링을 이용한 파이프라인
함수형 자료구조를 만드는 것에는 성공했지만 코드를 보다시피 사용하기에는 많이 불편하다. 함수 합성은 이전에 작성했던 코드 외에도 메서드 체이닝, 파이프라인 등 다양한 방법으로 사용할 수 있다. 여기서는 파이프라인을 구현해보자. 파이프라인은 함수를 연속적으로 실행하는 것을 의미한다. Elixir와 같은 언어는 파이프 연산자(|>)를 제공해주기도 하지만 TypeScript는 제공해주지 않는다. 그래서 직접 구현할 필요가 있다.
const pipe = (...fns: Function[]) => (x: any) => fns.reduce((v, f) => f(v), x);
const f = pipe(
(x: number) => x + 1,
(x: number) => x + 2,
(x: number) => x + 3,
);
console.log(f(0)) // 6구현은 어렵지 않다. pipe 함수도 고차 함수기 때문에 복잡할 수 있지만 내용을 보면 단순히 함수 배열을 reduce를 통해 순회하면서 함수를 실행해줄 뿐이다. 문제는 pipe 함수는 인자를 하나만 받기 때문에 앞서 작성한 함수 중 인자를 2개 이상 받는 함수는 수정이 필요하다. 이를 해결하기 위해서는 커링을 이용해야 한다. 커링은 함수를 인자를 하나만 받는 함수로 변환하는 것을 의미한다. 직접 앞서 구현한 여러 함수를 리팩토링 할 수도 있지만 여기서는 curry라는 함수를 만들어 변환해보자.
const curry = (fn: Function) => {
const curryFn = (...args: any[]) => {
if (args.length >= fn.length) {
return fn(...args);
} else {
return (...args2: any[]) => curryFn(...args.concat(args2));
}
}
return curryFn;
}위 함수를 사용하면 기존에 만들어진 함수를 조각낼 수 있다. 예를 들어 append 함수는 인자를 2개 받는 함수이다. 이를 커링을 이용하여 인자를 하나만 받는 함수로 변환해보자.
const list = Cons(1, Cons(2, Cons(3, null)));
const curriedAppend = curry(append);
curriedAppend(4)(list); // Cons(1, Cons(2, Cons(3, Cons(4, null))))이제 pipe 함수를 수정하여 인자를 2개 이상 받는 함수를 사용할 수 있도록 해보자.
// ... 앞서 구현한 함수들
const curriedAppend = curry(append);
const curriedUpdate = curry(update);
const curriedShift = curry(shift);
const list = Cons(1, Cons(2, Cons(3, null)));
const f = pipe(
curriedAppend(4),
curriedShift,
curriedUpdate(0, 10),
toArray,
);
console.log(f(list)); // [10, 3, 4]코드를 선형적이고 더 읽기 쉽게 만들어졌다.
마치며
필자에게 함수형 자료구조가 필요할까?라는 질문을 한다면 실무적인 부분에서 필요없다라고 답할 수 있다. 필자가 쉽게 설명하지 못하는 탓도 있지만 기존 자료구조보다 훨씬 더 복잡하고 어렵기까지 하다. 하지만 이 내용을 이해한다면 조금 더 코드를 작성하는 것에 재미를 붙일 수 있을 것이라 믿는다.








