
코드 잘짜기 위해서 뇌 과학까지 알아야하다니!!
평소 이 책에 대해서 극찬하는 글을 자주봤는데 기대했던 것 이상으로 좋은 책이었다. 평소에 올바른 코드란 무엇인지에 대해서 정말 많은 고민을 했는데 이 책을 접한건 큰 행운이라 생각된다. 읽기 전엔 위와 같은 생각이었지만 읽고 난 후에는 역시 지식은 넓을 수록 좋다는 것을 다시금 깨달았다.
기억 방식
이 책은 들어가며 간단한 코드 예제를 보여주며 예제 코드를 왜 읽기 힘든지, 왜 이해하기 어려운지를 설명하며 시작한다. 책 내용을 따르면 우리 뇌는 다음과 같은 세 가지 방식으로 기억한다고 한다.
- 장기 기억 공간 (Long term memory, LTM)
- 단기 기억 공간 (Short term memory, STM)
- 작업 기억 공간 (Working Memory)
위 세 기억 방식들에 대한 설명 이후로 이 책은 기억 방식을 통해 프로그래머가 어떻게 코드를 읽고 이해하는지, 그리고 뇌 과학에 기반하여 어떻게 코드를 작성하는 것이 좋은지 가이드해준다.
장기 기억 공간
먼저 장기 기억 공간(LTM)은 기억하는 내용을 반영구적으로 보관하는 곳이다. 즉, 지식을 저장하는 공간으로 이 공간이 코드를 작성할 때 어떤 작용을 하는지 알아보기 위해 다음 예제 코드를 살펴보자.
2 2 2 2 2 ⊤ n과연 프로그래밍 언어가 맞는지 의심스러운 위 예제 코드는 APL이라는 언어로 구현된 이진수 변환 프로그램이다. 간단히 언어에 대해 소개하자면 APL은 과거에 수학적인 계산을 위해 만들어진 오늘 날에는 거의 사용되지 않는 언어다.
책 내용에 따르면 위 코드에서 T는 수의 값을 다른 진법의 수로 변환해주는 함수라고 한다. 정말로 동작하는지 확인하고 싶다면 https://tryapl.org/에서 테스트를 할 수 있다.
수정 전 문장 “책 내용에 따르면 위 코드에서 T는 수의 값을 다른 진법의 수로 변환해주는 함수라고 한다. 정말로 동작하는지 확인해보고 싶어서 https://tryapl.org/에서 테스트를 해봤는데 동작이 안되어서 진짜인지는 모르겠다.”
kangmingu93님이 댓글로 사용 방법을 공유해주셨습니다. 사이트 상단에서T모양으로 보이는 아이콘을 사용하여 가능합니다. n 위치엔 변환할 수를 넣으면 됩니다.
ex) 2 2 2 2 2 ⊤ 10 ➡️ 0 1 0 1 0
아무튼 필자도 그랬지만 예제 코드를 보고나서 많은 혼란을 느꼈을 것이다. 일단 우리가 알던 프로그래밍 방식과 전혀 다르고 각 숫자와 문자가 무엇을 하는지 전혀 모르기 때문이다. 따라서 우리가 이 코드를 보고 혼란을 느끼는 이유는 지식의 부족 때문이라 할 수 있다. 지식이 없다는 것은 장기 기억 공간(LTM)에서 해당 지식이 없다는 것을 말한다.
따라서 코드를 해석할 때 필요한 지식은 장기 기억 공간에서 꺼내오게 된다. 지식이 부족하다면 우리는 코드를 해석하는데 어려움을 느끼게 된다.
단기 기억 공간
이어서 단기 기억 공간(STM)은 정보를 일시적으로 저장하는 공간이다. 말 그대로 정보를 일시적으로 저장하기 때문에 다른 정보를 찾는 과정을 거치거나 시간이 지나면 잊게 된다. 다음 예제 코드를 살펴보자.
public class BinaryCalculator {
public static void main(Integer n) {
System.out.println(Integer.toBinaryString(n));
}
}두 번째 예제 코드도 이진수 변환 프로그램인데, 이미 Java를 잘 아는 개발자라면 쉽게 느껴질 것이고 Java를 잘 모르더라도 대충 어디서 이진수 변환이 이루어지는지 알 수 있을 것이다.
이는 우리가 Binary, Calculator, to Binary 등에 대한 단어를 알고있고 공통된 프로그래밍 언어 문법을 지식으로 알고 있고 이를 LTM에서 꺼내오기 때문이다. 보통 이런 지식을 제외하고 로직을 이해할 때는 STM에서 정보를 저장하고 꺼내오는 과정을 수행하게 된다. 예를 들어, main 함수의 첫 줄을 읽을 때 우리는 입력받는 변수 n이 있고 이 변수가 정수형이라는 것을 알 수 있다. 이 함수가 어떤 일을 수행할지는 모르지만 일단 n은 계속 기억해둔 상태로 코드를 읽게된다. 다음 라인을 살펴보면 toBinaryString 메서드가 n을 받아 실행됨을 알게되고 이를 다시 기억하게 된다.
이 예제가 혼란스러울 수 있는 이유는 toBinaryString이 내부적으로 무엇을 수행하는지 알지 못한다는 점이다. 즉, 혼란의 원인은 정보의 부족이라 할 수 있다.
…라고 하지만 책에 나온 이 예제는 조금 아쉬운게 Integer.toBinaryString은 무엇을 하는지 충분히 구체적인 이름이기 때문에 정보가 부족하다는 느낌이 안든다. 그래서 필자가 새로운 예제를 만들어봤는데 한 번 살펴보자.
import java.time.*;
public class Sample {
public static void main() {
String year = "2022";
String month = "08";
String day = "05";
LocalDate localDate = LocalDate.parse(year + "-" + month + "-" + day);
System.out.println(localDate);
}
}위 코드는 Java의 LocalDate를 사용하여 날짜를 출력하는 예제이다. 여기서 필자는 LocalDate의 parse 메서드가 이해하기 혼란스러운 메서드라고 생각하는데 값을 어떻게 넣어야 하는지, 내부적으로 어떻게 수행되는지 메서드 이름만 봐서는 알 수 없기 때문에다. 물론 String을 DateTime으로 변환하는 규칙은 어느정도 공통적으로 정해진 규칙이 있지만 이런 규칙을 잘모르는 개발자라면 충분히 헷갈릴 수 있다고 생각한다.
그래서 결국 위 코드에서 parse라는 메서드가 어떤 것을 수행하는지, 수행하기 위해 어떤 데이터가 필요한지 정보가 부족하다 볼 수 있다. 이를 알기 위해선 별도로 LocalDate.parse 메서드 내부를 살펴보거나 문서를 읽어봐야 한다. 이러한 정보가 부족하다면 우리는 코드를 해석하는데 어려움을 느끼게 된다.
작업 기억 공간
작업 기억 공간은 우리가 사고할 때 사용하는 영역으로 LTM과 STM에서 가져온 지식과 정보를 처리하는 영역이다.
LET N2 = ABS(INT(N))
LET B$ = ""
FOR N1 = N2 TO 0 STEP 0
LET N2 = INT(N1 / 2)
LET B$ = STR$(N1 - N2 * 2) + B$
LET N1 = N2
NEXT N1
PRINT B$위 예제도 결국 이진수 변환 프로그램인데 BASIC 역시 오래된 언어기 때문에 지식적인 혼란이 발생할 수 있다. 그렇지만 APL처럼 너무 다른 정도는 아니기 때문에 변수명이나 연산자, 예약어 등을 통해 어떻게 동작하는지 유추할 수는 있다.
어려운 코드는 아니지만 위에서 봤던 Java 예제보다는 해석하는데 시간이 오래 걸렸을 것이다. 이는 머릿속에서 모든 과정을 처리하기 어렵기 때문으로 코드가 실행되는 것을 한눈에 파악할 수 없기 때문이다.
이런 일이 발생하는 이유는 처리 능력의 부족 때문이다. 변수에 임시로 저장되는 값을 전부 기억하며 각 단계를 처리한다면 모를까 필자처럼 평범한 사람은 메모하지 않는다면 위 로직이 어떤 일을 수행하는지 한눈에 알기 힘들 것이다.
인지 과정
책의 내용을 따르면 우리는 정보를 다음과 같이 처리하고 인지한다고 한다.
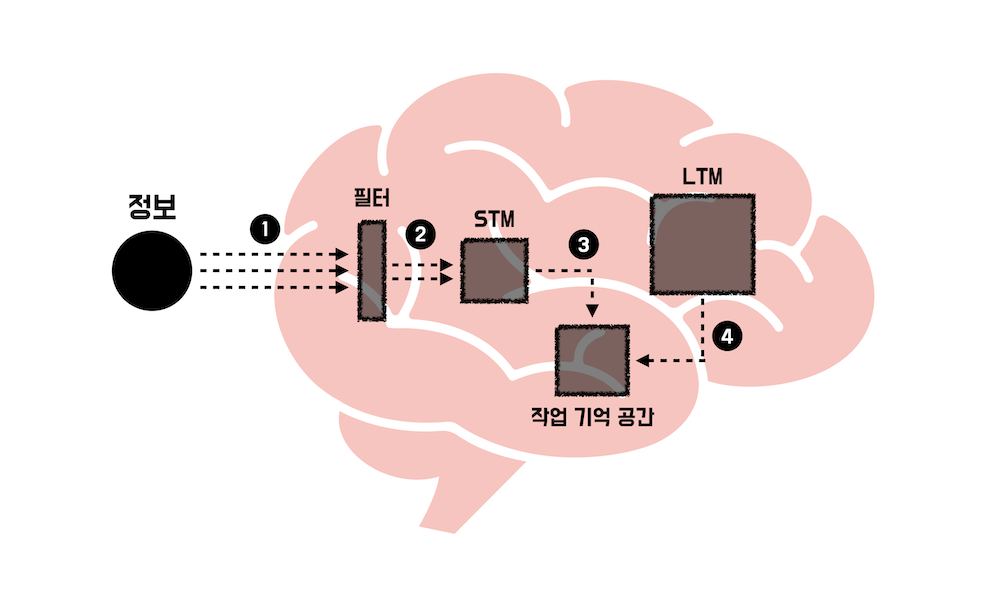
정보는 우리가 필요한 것들만 적당히 필터링되어 STM에 저장된다. 그리고 이렇게 저장된 정보는 작업 기억 공간에서 사용되고 필요하다면 LTM에서 지식을 가져와서 합쳐지게 된다. 위 도식은 책 전반에 걸쳐서 설명할 때 사용되는 도식으로 각 영역이 어떻게 동작되는지 쉽게 알 수 있다.
그래서 결국 이 책은 위에서 설명한 LTM, STM, 작업 기억 공간과 이 인지 과정을 핵심으로 우리가 코드를 어떻게 분석하고 작성해야 하는지, 어떻게 공부하고 훈련해야 하는지를 전반적으로 설명한다. 좋은 내용이 많기 때문에 꼭 읽어보는 것을 추천한다.
인상 깊었던 내용
책의 모든 내용을 이곳에 정리하는 것보단 한 번 꼭 읽어보는 것을 추천하는 책이다. 이 책에서 인상 깊었던 내용만 몇 가지 뽑아 정리하면 다음과 같다.
인지 부하
작업 기억 공간은 정보를 처리하는 역할로 한 번에 너무 많은 것을 처리하려 하면 과부하 상태가 된다고 한다. 이 부분은 사람마다 다를 수 있지만 협업을 한다는 것은 다양한 사람을 고려해야 한다는 것은 분명하다.
이 인지 부하를 줄이기 위한 방법도 책에 소개가 되어있는데 그중 인상 깊었던 것은 프로그래밍 언어의 구성 요소 중 생소할 수 있는 것은 다른 것으로 대체하는 것이다.
예를 들어, Python의 경우 흔히 없는 독특한 문법이 몇 가지 있는데 그 중 comprehension이라는 문법이 있다. 코드로 표현하면 다음과 같다.
# comprehension을 사용하지 않은 경우
sum = 0
for i in range(1, 10):
sum += i
print(sum)
# comprehension을 사용한 경우
print(sum(i for i in range(1, 10)))위 코드에서 윗부분과 아랫부분은 동일한 결과를 나타내는 코드다. 만약 comprehension을 아는 개발자라면 아래 코드도 이해하기 쉽겠지만 만약 모르는 개발자라면 가독성이 좋지 않을 것이라고 생각한다. 물론 보통은 같이 일하는 개발자들은 대체로 같은 기술 스택을 사용하기 때문에 이런 작은 부분에서 문제가 생기진 않겠지만 언제든지 다른 사람은 모를 수 있음을 염두에 두고 코드를 작성하는 것이 좋겠다고 느꼈다.
이름에 대하여
이 책에서는 함수, 클래스, 변수 이름에 대한 중요성도 말하고 있다. 이 부분에 대해서는 평소 선언적으로 작성하는 것이 중요하다고 생각하는데, 예를 들어 !isEmpty()와 isNotEmpty()를 보았을 때 어떤 것이 가독성에 좋은지 생각했을 때 큰 차이가 없다고 생각할 수 있지만 STM을 생각해보면 후자가 더 가독성에 좋다는 것을 알 수 있다. 이것처럼 프로그래밍 언어에서만 사용되는 규칙이나 특수 문자를 더하여 기억할 정보를 늘리는 것보단 정확한 단어를 사용하는 것이 가독성에 좋기 때문에 함수나 클래스, 변수명이 중요하다는 것에는 큰 공감을 했다.
기억의 크기 제한 극복
STM은 저장되는 시간 뿐만 아니라 용량이 2~6개로 제한된 크기를 가진다고 한다. 생각보다 상당히 적은 용량인데 이를 효과적으로 사용하기 위해선 청크라는 단위로 묶어 기억하는 것이 중요하다. 처음엔 무슨 소리인가 했는데 예제를 보니 무슨 말인지 완벽히 이해하게 됐다.
다음 문장을 5초간 본 후 어떤 문장이었는지 기억해보자.
abk mrtpi gbar
5초면 생각보다 짧기 때문에 다 외우지 못한 사람이 꽤 많을 것이다.
그럼 이번엔 다음 문장을 5초간 본 후 어떤 문장이었는지 기억해보자.
cat loves cake
이번엔 아주 쉬웠을 것이다. 아마 5초가 너무 길었을지도 모른다. 이런 차이가 발생한 이유는 기억해야 할 항목이 각각 다르기 때문이다. 앞 abk mrtpi gbar는 3개의 단어와 9개의 서로 다른 문자로 이루어져있다. 이는 STM의 용량을 훌쩍 넘어서는 크기기 때문에 외우기 어렵다. 반면, cat loves cake는 우리가 이미 알고있는 단어들로 이루어져있어 기억해야 할 항목이 3개 밖에 없다. STM 한도 이내기 때문에 외우기 쉽다.
이처럼 순간적인 기억의 크기에 제한이 있다는 점과 이를 극복하는 방법이 있고 이에 따른 훈련 방법도 있다는 점은 인상적이었다.
앞으로 어떻게 개발할까?
사실 책을 읽고 나서 앞으로 어떻게 하는 게 좋을까 고민했지만, 책에서 말한 것처럼 처음에 정한 규칙을 벗어나는 것은 쉽지않다. 그래도 부분적으로 개선할 수 있는 부분이 있을 것이라 생각하는데, 위에서 작성한 인상 깊었던 부분이 마침 평소에 고민하고 있던 부분과 일치해서 방향성이 잡힌 것 같다.
선언적으로 작성하기
본래 객체지향은 가독성이 좋지 않은 방법론이라고 한다. 그 이유는 객체의 관계를 한 눈에 알 수 없기 때문이다. 따라서 UML이나 문서를 보기 전까진 로직을 쉽게 파악하기 힘들다. 객체를 포기할 수는 없어도 어느 정도 가독성있게 작성할 수는 있을 것이라 생각한다. 클래스는 한 가지 책임을 가져야하고 함수는 한 가지 일을 해야한다라는 말은 객체지향 프로그래밍에서 굉장히 유명한 말이다. 물론 급하게 작성하거나 오버 엔지니어링이 될 수 있기에 이 유명한 말을 무시하는 경우도 종종 있다. 그렇지만 다시 이 점을 상기하고 함수의 추상 정도를 높이고 최대한 선언적으로 작성하려고 한다.
코드를 선언적으로 작성할 경우 다음과 같은 장점을 얻을 수 있다.
- 함수가 하나의 책임만을 가지면 동작에 대해 이해하기 쉬워진다. 따라서 추가 정보가 필요없도록 만들기 때문에 STM의 부하를 줄일 수 있다.
- 순차적으로 읽어도 이해하기 쉽다. 따라서 작업 기억 공간의 부하를 줄일 수 있다.
- STM의 용량 범위를 벗어나지 않도록 함수를 추상화할 수 있다.
예를 들어 코드로 표현하면 다음과 같다. 여기서는 너무 길어지지 않도록 클래스 선언은 제외한다.
// Kotlin
fun sumOfOddNumbers(n: Int): Int {
var sum = 0
for (i in 1..n) {
if (i % 2 == 1) {
sum += i
}
}
return sum
}
fun main() {
print(sumOfOddNumbers(10))
}위 코드는 n까지의 홀수 합을 구하는 단순한 코드다. 이렇게 사용해도 충분히 괜찮지만 다음과 같이 구현할 수도 있다.
fun main() {
print(
generateSequence(0) { it + 1 } // 코틀린에서 제공하는 함수 사용
.take(10)
.filter { it % 2 == 1 }
.fold(0) { a, b -> a + b }
)
}generator를 이용하여 지연 평가를 통해 구현하고 선언적으로 무엇을 필터링할 것인지, 필터링한 데이터를 어떻게 더할 것인지를 표현했다. 만약 이 부분을 좀 더 가독성 있게 만든다면 다음과 같이 표현할 수 있을 것이다.
fun generateSequentialList(n: Int) = generateSequence(0) { it + 1 }.take(n)
fun Sequence<Int>.filterOdd(): Sequence<Int> = this.filter { it % 2 == 1 }
fun main() {
print(
generateSequentialList(10)
.filterOdd()
.sum()
)
}위처럼 이미 작성된 코드를 통해 좀 더 선언적으로 작성하는 것도 가능하다. 지연 평가를 안 쓰더라도 다음과 같이 함수 합성을 통해 작성하는 것도 가능하다.
infix fun <F : (T1) -> T2, T1, T2, T3> F.andThen(n: (T2) -> T3): (T1) -> T3 = { n(this(it)) }
fun createSequentialList(n: Int) = List(n) { it + 1 }
fun filterOdd(list: List<Int>) = list.filter { it % 2 == 1 }
fun sum(list: List<Int>) = list.sum()
fun main() {
val sumOfOddNumbers = ::createSequentialList andThen
::filterOdd andThen
::sum
print(sumOfOddNumbers(10))
}사실 이 부분은 사실 함수형 패러다임이 들어가기 때문에 기초가 되는 코드를 작성하는 것은 어려울 것이라 생각한다. 하지만 일단 기초가 되는 코드를 작성하고 나면 쉽게 확장하고 재사용 할 수 있다는 것이 장점이다. 그리고 로직을 순차적으로 봐도 이해할 수 있도록 개선하는 것이 가능하다. 물론 말은 쉽고 행동은 어렵기 때문에 얼마나 적용할 수 있을지는 모르겠다.
그리고 단점이 없는 것은 아닌게 함수 단위가 작아진다는 것은 외워야하는 함수가 많아진다는 것을 의미한다. 이는 LTM에 문제가 되지 않을까? 아무튼 좋은 코드를 작성하는 길은 너무나도 험난하다.
결론
잘모르는 뇌 과학적인 요소가 나오기 때문에 처음엔 읽기 어려울 것이라 생각했지만 생각보다 읽는 것이 어렵진 않았다. 그리고 내용에 대해 충분한 연구 결과를 근거로 제시하기 때문에 책에 대한 신뢰성을 가질 수 있다.
아무튼 굉장히 인상 깊고 신선한 책이었다. 아직 올바른 코드란 무엇인가에 대한 고민이 전부 해결되진 않았지만, 이 책을 읽고 나서 안개가 걷힌 기분을 느꼈다. 아직 조금 덜 읽었는데 빨리 남은 내용도 읽어야겠다.








