
새는 알에서 나오기 위해 투쟁한다. 알은 세계이다. 태어나려고 하는 자는 누구든 하나의 세계를 파괴하지 않으면 안된다. - 헤르만 헤세, 데미안
소프트웨어 개발은 많은 부분이 애매모호하다는 생각을 해본 적이 있는가? 무엇을 만들어야 하는지, 어떤 방식으로 개발해야 하는지, 만든 것이 제대로 된 것인지 등 우리는 무엇하나 확신할 수 없다. 끊임없이 물음을 던지기 때문에 개발이 재밌는 것이겠지만 성과를 달성해야 할 때는 답답한 문제가 된다.
이는 많은 개발자를 괴롭히는 고민이 아닐까 싶다. 개발자는 완벽한 구현을 위해 패턴, 설계, 방법론 등을 학습하지만 은총알은 없다는 사실에 좌절한다. 이렇게 되는 이유는 결국 소프트웨어 개발의 많은 부분이 불확실하기 때문이다. 이는 정말 안타까운 개발자의 비극이다.
불확실성에 대항하는 방법
대체 소프트웨어 개발은 왜 불확실한걸까? 여러 이유가 있겠지만 필자 개인의 경험, 많은 서적, 주변의 이야기를 들어보면 결국 비즈니스라는 괴물이 존재하기 때문이다. 소프트웨어 개발은 비즈니스를 만났고 더 이상 기술만을 논의할 수 없게 되었다.
비즈니스라는 괴물
비즈니스는 어마어마한 복잡성을 가진다. 마치 혼돈이라고 말해도 과언이 아니다. 우리의 가설은 언제나 틀릴 수 있고 그로 인해 요구사항은 계속해서 변한다. 설령 요구사항을 고정했더라도 시장은 끊임없이 변화하며 우리는 이에 대응해야 한다. 따라서 개발자의 예측은 높은 확률로 틀릴 수 밖에 없다.
개발자는 공든 탑을 쌓는다. 요구사항을 분석하고 설계를 하며 코드를 작성한다. 그렇지만 요구사항이 변하면 탑은 무너질 수밖에 없다. 아이러니하게도 좋은 소프트웨어를 만들기 위해 노력한 것이 기술부채로 변하게 된다.
어쩌면 이런 일은 초기 제품 단계에서 일어나는 일이 아닌가?라는 의문이 생길 수 있다. 그 말처럼 초기 제품 단계에서는 이런 일이 많이 일어난다. 그러나 제품이 성숙해져도 문제는 사라지지 않는다.
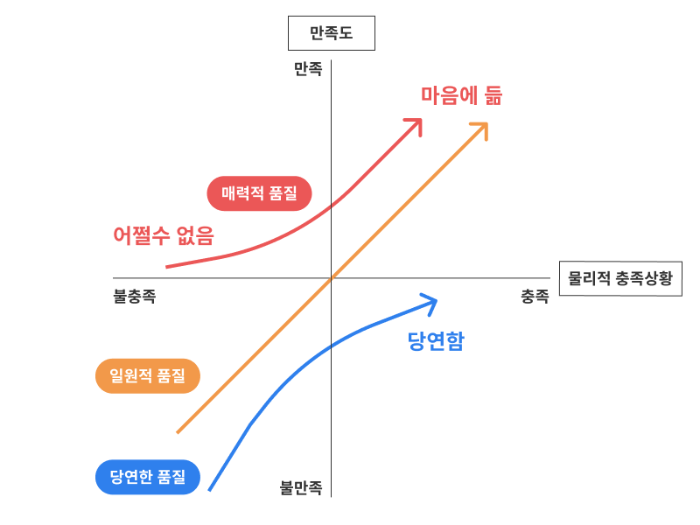
위 사분면 다이어그램은 카노 모델로 제품의 특성에 따라 고객의 만족도를 분석하는 모델이다. 간단하게 설명하자면 로그인, 회원가입과 같은 기능은 당연한 품질이고 그 제품을 구매하는 이유가 되는 독특한 기능은 매력적인 품질이라고 할 수 있다. 이 모델에서 중요한 것은 시간이다. 아무리 매력적인 품질이 시장에 나오더라도 시간이 지나면서 그 만족도는 떨어진다. 왜냐하면 매력적인 품질은 시간이 지날 수록 당연한 품질이 되기 때문이다.
예를 들어 모바일 앱이 처음 등장하던 시기에는 모바일 앱 자체가 매력적인 품질이었다. 그래서 서비스를 출시하는 것만으로 주목받고 사용해보는 사람이 많았다. 그러나 시간이 지나면서 모바일 앱이라는 것 자체는 더 이상 매력적이지 않고 당연한 품질이 되었다. 이젠 많은 모바일 앱 서비스는 새로운 매력을 찾아야만 살아남을 수 있다.
여기서 얻을 수 있는 교훈은 비즈니스의 복잡도는 시간이 지나도 죽지 않는다는 것이다. 비즈니스적 가치는 시간이 지날수록 감가상각된다. 시장은 끊임없이 변화하고 경쟁자 또한 계속해서 등장하므로 감가상각된 가치는 도태될 수 밖에 없다. 이러한 위협에 생존하기 위해 비즈니스 전략이 바뀌는 것은 당연하다. 비즈니스에 의존하는 코드는 시간이 지나며 감가상각된다. 당시에 완벽했던 코드도 시간이 지나면 가치가 사라질 수 밖에 없다.
지식과 경험의 부족
작은 이유는 개발자의 지식과 경험이 부족하기 때문이다. 우리는 왜 리팩터링을 할까? 당연하게도 이해하기 힘들거나 수정하기 어려운 코드를 개선하기 위해서다. 그런데 왜 코드를 이해하기 힘들거나 수정하기 어려운 코드가 나오는 걸까? 그 이유는 개발자의 지식과 경험이 부족하기 때문이다.
리팩터링은 지식과 경험에 기반한 기술이다. 패턴을 인식하고 올바르게 접근해야 더 좋게 개선할 수 있다. 만약 적절한 기술을 사용할 수 없다면 다시 작성해도 또 다시 리팩터링해야하는 상황이 올 수 있다. 그래서 리팩터링이란 결국 지식과 경험이 부족했기에 해야하는 개발자 스스로 만들어낸 기술부채라고 할 수 있다.
지식과 경험의 부족을 작은 이유라 표현한 이유는 내부 요인이기 때문이다. 비즈니스의 복잡성은 개발자가 통제할 수 없는 외부 요인이다. 하지만 지식과 경험은 개발자가 통제할 수 있는 내부 요인이다. 시간이 허락한다면 언제든 지식과 경험을 쌓아 문제를 해결할 수 있다. 그러나 비즈니스의 변화는 개발자가 통제할 수 없다.
비극의 탄생
개발자는 더 좋은 소프트웨어를 만들기 위해 끊임 없이 노력한다. 수많은 방법론, 아키텍처 패턴, 리팩터링 기술 등을 학습하고 이는 실제로 문제를 해결하는데 많은 도움을 준다. 구현만으론 부족하다고 느낀 개발자는 설계를 배우고 설계의 트레이드 오프를 경험한 개발자는 유동적으로 움직일 수 있는 방법론을 배운다. 그러다보면 비즈니스까지도 공부하게 되는 순간이 온다.
그럼에도 불구하고 완벽할 수는 없다는 것을 깨닫게 된다. 완벽할 수 없다면 확신할 수 없고 나는 언젠가 삭제할 수 밖에 없는 코드를 만드는구나라는 생각을 하게 된다. 우리는 이런 상황에서 어떻게 행동해야 할까?

재밌게도 과거에 위대한 철학자가 방향을 제시해줬다. 니체는 위대한 철학가지만 예술을 사랑했다. 그래서 니체는 그의 첫 작품인 비극의 탄생에서 예술을 방향성에 대해 설명했고 이 내용은 우리 개발자에게도 교훈을 준다.
비극의 탄생에선 두 힘이 언급된다. 첫 번째는 경계를 파괴하는 힘으로 현실, 자연, 무질서, 파괴, 죽음과도 같은 것을 말하고 디오니소스적인 것이라 표현했다. 두 번째는 경계를 인식하고 나누는 힘으로 분석, 분류, 검증, 이성과도 같은 것을 말하고 아폴론적인 것이라 표현했다. 니체는 아폴론적인 것은 디오니소스적인 힘에 대항하는 이성적인 방법이라 말했다.1
의외로 이 이야기는 소프트웨어 개발에도 딱 맞는다. 니체의 이야기를 소프트웨어 개발에 적용해보자. 예술과 동일하게 소프트웨어 개발은 디오니소스적인 것과 아폴론적인 것이 대립하는 것이라 할 수 있다.
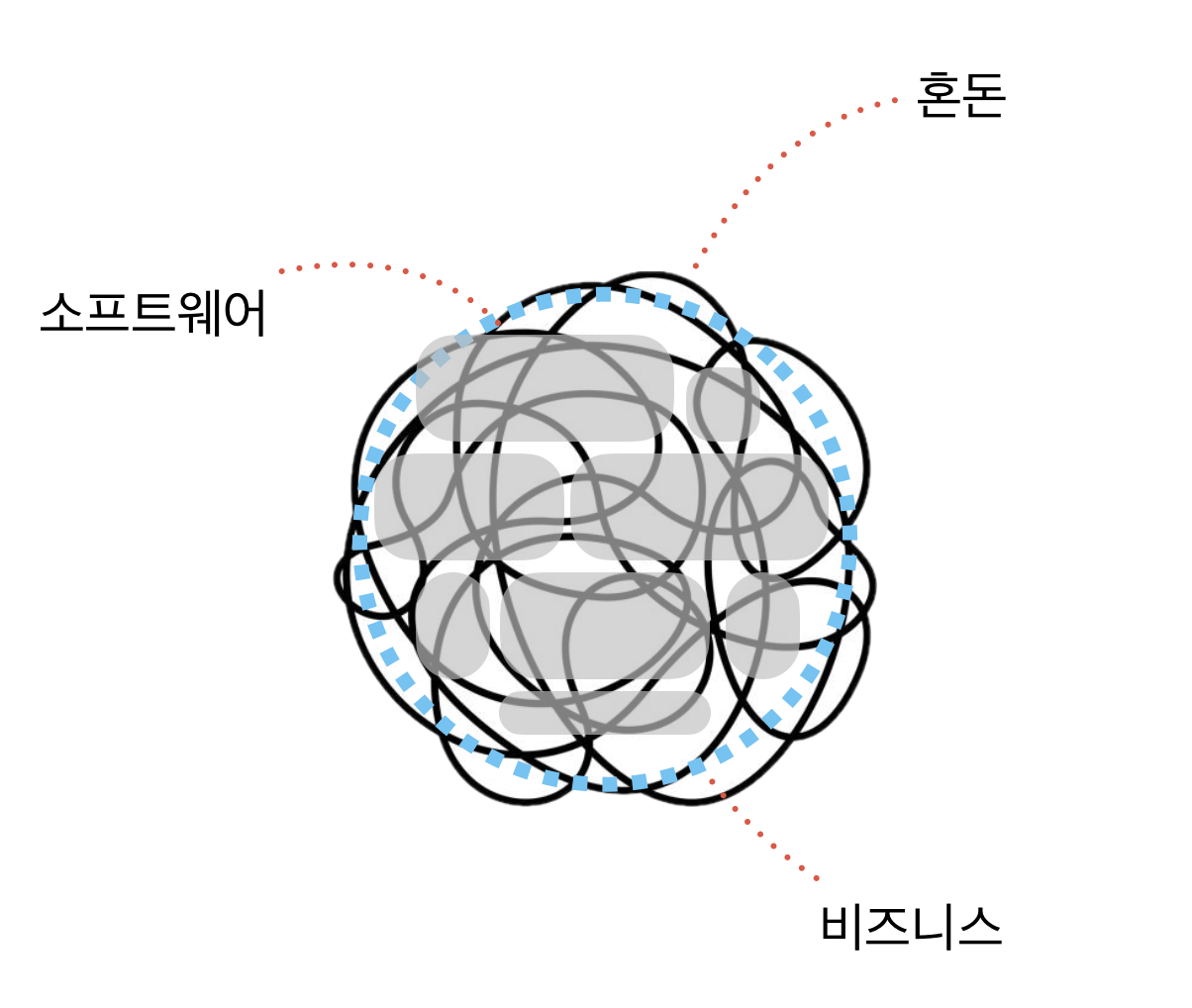
가운데 스파게티처럼 꼬인 선은 혼돈이다. 이는 사람일 수도 있고 비즈니스가 다루고자하는 복잡성일 수도 있다. 이러한 복잡성은 디오니소스적인 힘이다. 비즈니스는 이런 복잡성에 경계를 두고 분석하여 이익을 얻는 행위다. 개발자는 또 다시 그 경계에 맞춰 모델링을 하고 모듈을 만들고 객체간의 협력을 구현하며 소프트웨어를 만든다. 이는 아폴론적인 힘이다.
이대로 완성되면 완벽하겠지만 꼬여버린 혼돈은 계속해서 바뀐다. 비즈니스가 그어놓은 경계를 벗어나며 모양을 마음대로 바꾸고 우리가 만든 설계를 마구 헤집고 파괴한다. 그럼 우리는 결국 다시 만들 수밖에 없다. 그야 말로 비극이다.
개발자의 세 가지 길
완벽할 수 없다는 것을 깨달은 개발자는 세 가지 길 중 하나를 선택할 수 있다. 하나는 염세주의적 태도를 취하는 것이다. 여기서 염세주의적 태도는 디오니소스적인 것에 대항하는 것은 무의미한 일이라고 생각하는 것이다. 즉, 디오니소스적인 것2에 굴복하는 것이다. 이 길에 빠지면 보통 다음과 같은 말을 한다.
- 어차피 바뀔테니 그냥 만들자
- 설계, 방법론같은 것은 무의미해
- 애자일은 제대로 돌아가는 걸 본 적이 없어
근거가 없는 말은 아니라고 생각하지만 과연 이게 옳은 태도일까? 직접 물어보면 대부분 아니라고 말할 것이다. 그렇지만 실제로는 많은 개발자가 염세주의적인 태도를 취한다. 스스로 선택해서 그런 것이 아니라 자기도 모르는 사이에 그렇게 된 경우가 많다. 왜냐하면 편하고 안락한 길이기 때문이다.
두 번째는 기술에만 집중하는 것이다. 즉, 이 길은 불합리한 디오니소스적인 것에서 도피하여 이상적인 가상을 만들어내는 아폴론적인 것만을 집중하는 것이다. 이런 경우 특정 기술을 신봉하여 경직되고 획일화된 사고를 가지게 된다.
- TDD로 모든 문제를 해결할 수 있어
- 클린 아키텍처는 언제나 옳아
- C++ 외에는 전부 쓰레기야
이런 사고에 빠진 사람은 기술에만 집중하고 비즈니스를 무시하는 방향으로 나아간다. 디오니소스적인 것을 외면하는 것이라 볼 수 있다. 니체의 사상을 따르면 개발자는 매우 아폴론적인 사람이기에 기술이 모든 것을 해결해줄 것이라는 믿음을 쉽게 가진다. 기술은 그 자체로 가치가 있지만 기술이 모든 것을 해결해주는 일은 아직까지는 없었다. 이 길을 선택하는 개발자도 많다. 왜냐하면 쉬운 길이기 때문이다.
마지막으로 맞서 싸우는 것이다. 파괴적인 디오니소스적인 힘을 인정하고 받아들이는 것이라 할 수 있다. 조금 더 쉽게 얘기하자면 '완벽할 수 없다는걸 알았어. 그런데 그게 뭐? 나는 그래도 완벽을 추구하며 더 나은 방법을 찾아볼거야' 같은 사고라 할 수 있다. 이 길을 걷기 위해서는 가혹한 문제를 외면하지 않고 끊임없이 더 나은 길을 위해 개척하고 발굴해야 한다. 누군가는 비웃을수도 있다. 그래서 이 길은 어렵고 견뎌야하는 길이다. 니체는 그리스 비극에서의 영웅들처럼 비극적인 일을 겪어도 살아가는 것처럼 우리도 디오니소스적인 현실을 직시하고 어렵고 견뎌야하는 길을 걸어야 한다고 말했다.
혼돈에 대항하는 소프트웨어 역사
소프트웨어 개발은 지금까지 계속하여 혼돈에 대항해왔다. 처음엔 기술로서 단순 계산기로 시작했지만 점점 발전하여 많은 것을 하게 된 이후로 소프트웨어는 비즈니스를 만났다. 그래서 경제적이고 생산성을 끌어올리기 위한 방법을 연구하기 시작했다.
처음에는 비즈니스와 설계, 구현을 나눴지만 이는 결국 불확실성을 해결하지 못했다. 설계와 구현을 나누고 효율적으로 전달하기 위해 MDA3와 같은 방법론이 등장했지만 많은 실패를 겪었고, 비즈니스, 설계, 구현을 순차적으로 진행하는 폭포수 방법론 또한 비즈니스의 복잡성 앞에서 무너졌다. 그래서 더 나은 방법을 찾기 위해 많은 사람이 고민했고 이는 결국 비즈니스와 설계, 구현의 벽을 허무는 DDD나 애자일이라는 방법론으로 이어졌다. 애자일은 불확실성을 받아들이고 더 나은 방법을 찾기 위해 노력하는 방법론이다. 이는 디오니소스적인 힘을 인정하고 받아들이는 것이라 할 수 있다.
그럼 이 다음은 무엇이 등장할까? 지금도 수많은 사람들의 고민과 의견이 오가겠지만 지금은 알 수 없다. 필자 또한 고민하는 개인이지만 혼돈에 대항하는 개발자로서 한 가지 제안을 해볼 것이다.
파괴 지향 개발
앞서 좋은 이야기를 했지만 현실을 보면 어차피 지워진다라는 염세주의적 생각에 빠지기 쉽다. 우리가 열심히 작성한 코드가 실패작이라 느끼며 스스로 지우는 것은 매우 고통스럽기 때문이다. 그렇다면 차라리 거꾸로 생각하여 차라리 잘 지울 수 있게 만드는 것은 어떨까?
즉, 파괴에는 파괴로 대응하는 것이다. 이런 기초적인 아이디어로 필자는 파괴 지향 개발(Destruction-Oriented Development)이라는 것을 생각했다.
파괴는 좋은 것인가?
파괴라는 말이 들어가니 굉장히 부정적으로 보일 수 있다. 그렇지만 과연 정말로 파괴는 안좋은걸까?

파괴가 없다면 새로운 것은 탄생할 수 없다. 그것만으로 파괴는 충분히 좋은 방향으로 이끌 수 있다. 정말 그럴까? 소프트웨어에서 발생하는 파괴를 살펴보자.
소프트웨어에서 파괴는 크게 두 가지로 나눌 수 있다. 첫 번째는 기능을 삭제하는 것이다. 기능을 완전히 삭제할 수도 있고 다른 기능으로 재구현할 수도 있다. 이는 비즈니스 용어로 피벗이라 부른다. 피벗은 마음 아프지만 조직과 제품이 더 좋은 길로 나아갈 수 있는 기회를 부여한다. 경제적으로도 매몰비용의 오류에 빠지지 않으므로 좋은 방향으로 나아갈 수 있다.
두 번째는 같은 기능을 다시 만드는 것이다. 우리가 잘아는 리팩토링이라 할 수 있다. 소프트웨어는 시간이 지날 수록 가치를 잃어가고 낡는다. 리팩토링은 그런 소프트웨어의 생명을 연장시키는 행위로 소프트웨어가 오래 살아남기 위해선 꼭 필요한 일이다.
그래서 파괴 지향 개발이란?
본론으로 돌아가 파괴 지향 개발이란 무엇일까? 필자가 생각하는 파괴 지향 개발은 언젠가 코드가 파괴될 것이라는 사실을 받아들이고, 그것을 지향하여 개발하는 방법론이며 다음과 같은 세 가지 대원칙을 지향한다.
- 불확실성이 있다면 가능한 만큼 불확실성을 줄인다.
- 여러 방법을 선택할 수 있다면 파괴하기 쉬운 쪽을 선택한다.
- 필요한 것만을 유지한다. 따라서 필요 없는 것은 전부 지운다.
대원칙에 따라 개발한다면 다음과 같은 프로세스를 따를 수 있다.

위와 같은 프로세스를 진행하여 내부 요인에 따른 불확실성을 줄이고 어쩔 수 없는 외부 요인으로 인한 파괴에 대비하는 것이 핵심이다. 조금 더 자세히 알아보자.
경계 분리
먼저 불확실성에 따라 경계를 분리해야 한다. 불확실성은 변화율이며 이를 기반으로 분리하는 것이 가능하다.
- 외부 요인
- 기능이 실험적인가?
- 기능이 릴리즈 되었는가?
- 고객의 반응이 어떤가?
- 기능이 릴리즈된 후 얼마나 지났는가?
- 기능이 복잡한가?
- …
- 내부 요인
- 적절한 지식과 경험이 있는 상태에서 만들었는가?
- 코드에 신뢰성이 있는가?
- 코드를 이해할 수 있는가?
- 목표 성능을 달성했는가?
- …
변화율은 두 가지로 나눌 수 있다. 첫 번째는 외부 요인으로 이는 개발자가 통제할 수 없다. 두 번째는 내부 요인으로 이는 개발자가 통제할 수 있는 영역이다. 개발자는 외부 요인에 대비하며 최대한 내부 요인으로 인한 변화율을 줄여야 한다. 각 요인의 변화율은 조직마다 다를 수 있기 때문에 고정적인 수치로 표현하는 것은 불가능하다. 따라서 어느정도 휴리스틱한 방법으로 측정해야 한다. 개인적인 생각으로는 스토리 포인트를 측정하는 방법과 유사하게 측정하면 괜찮지 않을까라고 생각했다.
실제로 분리는 어떻게 이루어져야 할까? 먼저 분리 단위부터 정해야 한다. 분리 단위는 일반적인 소프트웨어 설계에서 다루는 것과 같다. 애플리케이션, 모듈, 컴포넌트, 유즈케이스, 클래스, 메서드 등 큰 범위에서 작은 범위까지 다양한 단위에서 분리가 가능하다. 각 단위는 서로를 침범해서는 안되며 무엇을 기준으로 분리할지 추상화 레벨을 결정해야 한다. 어렵게 느껴진다면 다음 내용을 참고하여 분리해보자.
- 각 코드는 완성된 이후 시간이 지날 수록 변화율이 높아진다.
- 지원 서브 도메인4에 가까울 수록 변화율이 낮다.
- 단일 책임 원칙이 지켜질 수록 변화율이 낮다.
- 독립적으로 존재할 수 있다면 바로 분리할 수 있다.
- 대신 인터페이스 만으로 통신할 수 있게 만들어야 한다.
- 불확실성을 측정할 수 없다면 억지로 분리하지 않는다.
- 큰 단위에선 분리하지 않더라도 불확실성을 판단할 수 있는 추상화 단위에서 분리한다.
파괴 가능성
변경하기 쉽게 만들고, 쉽게 변경하라 - 켄트 벡
경계를 분리했다면 이제 구현에 들어가야 한다. 구현을 할 때는 대원칙에 따라 파괴하기 쉬운 쪽을 선택해야 한다. 그런데 파괴하기 쉽다는 것을 어떻게 측정할까?
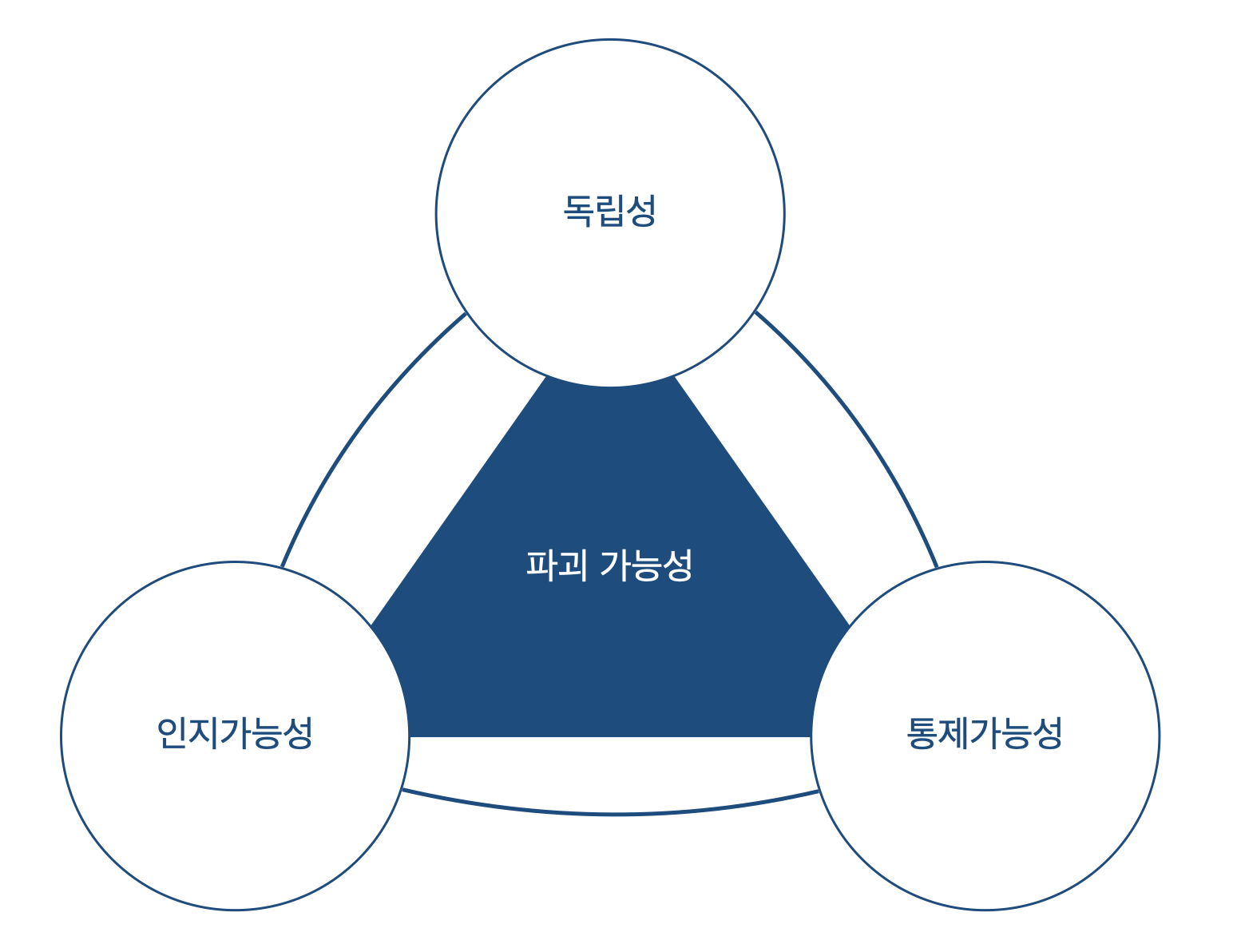
필자는 각각 독립성, 인지가능성, 통제가능성을 고려하여 파괴 가능성을 판단할 수 있다고 생각했다. 좀 더 풀어서 설명해보겠다.
독립성은 결합도와 응집도의 정도, 단일 책임 원칙을 어느정도로 지켰는지로 판단할 수 있다. 코드는 독립적일 수록 파괴하기 쉽다.
인지가능성은 말 그대로 개발자가 코드를 보고 이해할 수 있는 정도를 말한다. 예를 들어, 가독성이 좋지 않다면 확신을 얻을 수 없으므로 파괴하기 어렵다.
통제가능성은 개발자가 통제할 수 있는 영역인지를 말한다. 코드 오너십이 흐려져 그 누구도 관리하는 사람이 없다면 통제하기 힘든 코드가 된다. 그리고 작성된 코드가 문제가 있을 수도 있다면 마찬가지로 파괴하기 어렵다. 사회성은 언어의 사회성과 유사하다. 조직 내에서 약속하지 않은 규칙으로 코드를 작성하거나 어려운 문법을 사용한다면 사회적이지 않다고 표현할 수 있다. 예를 들면, 독자적인 DSL을 구현하고 아무에게도 설명하지 않았다면 사회성이 떨어지는 코드라고 할 수 있다.
복잡성 제거
마지막으로 불필요한 것이 있는지 확인하고 제거해야 한다. 즉, 최종적으로 코드베이스엔 필요한 것만을 남겨야 한다. 추억과 애정이 담긴 코드여도 예외는 없다.

보통 개발자는 혹시나 하는 마음에 지우지 않는다. 마치 우리가 혹시나 하는 마음으로 집에 보관하는 많은 잡동사니와도 같다. 그러나 이는 불필요한 것을 남겨두는 것이며 결국 코드베이스를 더 복잡하게 만든다. 따라서 필요 없는 것은 바로 지우는 것이 좋다. 그래도 불안하다면 지워도 보통 커밋 기록에 남아있기 때문에 복구가 가능하다는 것을 기억하자.
그리고 파괴 가능성이 낮은 코드는 리팩터링하거나 다시 만들어야 한다. 이는 내부 요인에 해당하는 변화율을 줄이기 위한 것이다. 만약 마감일에 대한 문제로 인해 작업하는 것이 어렵다면 기록만 해두고 작업해도 문제는 없다. 왜냐하면 내부 요인은 통제가 가능하기 때문이다. 파괴에 대비하여 최대한 단순성을 유지하는 것이 핵심이라는 것만 잊지말자.
코드 파괴의 기술
지금까지 이야기한 것은 소프트웨어를 관리하는 방법론이기 때문에 깔끔한 코드가 중요한 것은 아니다. 또한, 많은 곳에서 언급하는 설계 원칙, 구현 원칙을 잘 지킨다면 자연스럽게 파괴하기 좋은 코드가 만들어진다. 중요한 것은 확장에 대한 본능을 억누르고 파괴에 대비하는 것이다.
그렇지만 말로만 듣는다면 실제로 어떻게 진행해야할지 어려울 수 있다. 그러므로 파괴에 대응하기 위한 괜찮은 코드 작성법에 대해 알아보자.
단계 분리하기
단계를 분리하면 필요한 부분만 재작성하는 것이 가능하다. 그리고 대체로 프로그래밍 로직은 단계별로 나눠서 작성하는 것이 가능하다. 왜냐하면 대부분의 프로그래밍 로직은 전처리, 계산, 후처리와 같은 형태를 지니기 때문이다. 다음 예제를 살펴보자.
// 🟢 전처리, 계산, 후처리가 분리되어 있다
fun makeFibonacciList(n: Int): List<Int> {
val list = mutableListOf(0, 1)
for (i in 2 until n) {
list.add(list[i - 2] + list[i - 1])
}
return list
}
fun listSum(list: List<Int>): Int {
return list.sum()
}
fun main() {
val list = makeFibonacciList(10) // 데이터 생성
val sum = list.sum() // 로직
print(sum) // 출력
}
// 🔴 전처리, 계산, 후처리가 섞여있다
fun fibonacciSum(n: Int): Int {
var sum = 0
var a = 0
var b = 1
var c = 0
for (i in 0 until n) {
// 데이터 생성과 동시에 계산
if (i <= 1) {
sum += i
} else {
c = a + b
sum += c
a = b
b = c
}
}
return sum
}
fun main() {
print(fibonacciSum(10)) // 출력
}꼭 위와 같이 전처리, 계산, 후처리 단계로만 분리할 필요는 없다. 로직이 복잡해질수록 더 많은 단계로 분리할 수 있다. 이는 리팩터링 기법 중 단계 쪼개기를 이용할 수 있다.
참조 투명성 지키기
참조 투명성은 같은 입력에 대해 항상 같은 출력을 보장하는 것을 말한다. 순수 함수나 불변 객체를 이용하면 참조 투명성을 지키기 쉽다. 만약 불가피한 경우 최소한 멱등성을 지니도록 작성해야 한다.
// 🟢 순수 함수
fun factorial(n: Int): Int {
if (n == 0) {
return 1
}
return n * factorial(n - 1)
}
// 🟢 사이드 이펙트가 있지만 멱등성을 지닌 함수
val cache = mutableMapOf<Int, Int>()
fun factorial(n: Int): Int {
if (n == 0) {
return 1
} else if (cache.containsKey(n)) {
return cache[n]!!
}
val result = n * factorial(n - 1)
cache[n] = result
return result
}
// 🔴 참조 투명성이 없는 함수
var n = 1
fun factorial(): Int {
if (n == 0) {
return result
}
result *= n
return factorial(n - 1)
}참조 투명성을 지키지 않았을 때 가장 크게 발생할 수 있는 문제는 잘 돌아갈 때라고 할 수 있다. 차라리 문제가 발생한다면 수정하겠지만 잘 돌아가는 경우 영향을 미치는 모든 곳이 불확실해진다. 이런 경우 함부로 건들면 결함이 생길지도 모른다는 불안감이 생겨 삭제하기 힘들어진다.
단일 책임 원칙
단일 책임 원칙은 객체나 함수가 하나의 책임만을 지녀야 한다는 원칙이다. 잘 지켜질 수록 파괴 가능성이 높아지지만 가장 이해하기 쉬우면서 가장 적용하기 어려운 원칙이라 생각한다. 단일 책임의 기준은 무엇일까? 예를 들어 다음 코드는 단일 책임 원칙을 지키는가?
class UserInfo {
val userId: Long
val userName: String
val email: String
val telephone: String
val provinceAddress: String // 도
val cityAddress: String // 시
val regionAddress: String // 구
val detailAddress: String // 상세 주소
val avatarUrl: String
val createdAt: OffsetDateTime
val updatedAt: OffsetDateTime
val lastLoginAt: OffsetDateTime
}위 코드는 디자인 패턴의 아름다움에서 발췌한 코드로 위 코드에는 두 가지 견해가 있을 수 있다.
- 🙆♂️ 사용자와 관련된 정보가 포함되어 있고 모든 속성과 메서드가 사용자와 같은 비즈니스 모델에 속해 있어 만족한다.
- 🙅♂️ 주소 정보와 시간 정보에 대한 비율이 상대적으로 크기 때문에 UserAddress로 분리할 수 있어 책임을 분리할 수 있다.
둘 다 타당한 견해이며 어느 것이 옳다고 할 수 없다. 이런 경우에는 요구사항을 잘 살펴봐야 한다. 만약 UserAddress로 분리하더라도 해당 객체를 다른 곳에서 사용할 일이 없다면 나누지 않아도 된다. 하지만 사용할 일이 있다면 이 클래스는 단일 책임 원칙을 위배하는 것이므로 UserAddress로 분리해야 한다.
인터페이스 분리 원칙
클라이언트는 필요하지 않은 인터페이스에 의존하면 안된다라는 원칙으로 쉽게 얘기하자면 인터페이스 계의 단일 책임 원칙이라 할 수 있다. 이 원칙을 잘 지킨다면 기능을 제거할 필요가 있는 경우 인터페이스를 지우기만 하면 된다. 조금 단순하면서도 뻔한 예제를 살펴보자.
interface Bird {
fun fly()
fun walk()
fun swim()
}
class Sparrow : Bird {
override fun fly() = // ...
override fun walk() = // ...
// 🔴 참새는 수영을 못하는데? 일단 비워둘까?
override fun swim() = // ...
}
class Penguin : Bird {
// 🔴 펭귄은 못나는데..
override fun fly() = // ...
override fun walk() = // ...
override fun swim() = // ...
}
class Ostrich : Bird {
// 🔴 walk만 구현하면 되는데 쓸때없이 다 구현해야하네...
override fun fly() = // ...
override fun walk() = // ...
override fun swim() = // ...
}위 코드를 보면 Bird 인터페이스는 fly, walk, swim 세 가지 메서드를 지니고 있다. 그런데 Sparrow는 수영을 할 수 없고 Penguin은 날지 못한다. 그럼에도 인터페이스로 인해 구현해야 하는 메서드가 존재한다. 이런 경우 인터페이스를 분리하여 각각의 책임을 지닌 인터페이스로 나눌 필요가 있다.
// 🟢 이제 필요한 것만 상속받아 구현할 수 있다!
interface Flyable {
fun fly()
}
interface Walkable {
fun walk()
}
interface Swimmable {
fun swim()
}
class Sparrow : Flyable, Walkable {
override fun fly() = // ...
override fun walk() = // ...
}
class Penguin : Walkable, Swimmable {
override fun walk() = // ...
override fun swim() = // ...
}
class Ostrich : Walkable {
override fun walk() = // ...
}위처럼 인터페이스를 나누면 필요한 것만 상속받아 구현할 수 있다. 확장에도 도움이 되지만 필요없어진 기능을 파괴하는 것도 간단해진다.
스트랭글러 무화과 패턴
스트랭글러 무화과 패턴은 마틴 파울러가 여행가서 떠올린 패턴으로 주로 레거시 코드를 교체할 때 사용하는 패턴이다. 대체로 마이크로서비스 아키텍처에서 시스템을 교체할 때 자주 언급되지만 코드 레벨에서도 적용할 수 있다. 기존 코드를 교체하는 것이 아니라 새로운 코드를 추가하고 기존 코드를 감싸는 방식을 통해 기존 코드를 교체하는 방법이다. 적절하지 못한 시기와 상황 혹은 시간 등의 문제로 한 번에 기존 코드를 교체할 수 없다면 이 패턴이 유용하다. 다음과 같은 코드가 있다고 가정해보자.
class Object {
fun oldMethod1() {
// ...
}
fun oldMethod2() {
// ...
}
}위 코드를 교체하고 싶다면 다음과 같이 새로운 코드를 추가하고 기존 코드를 감싸는 방식으로 교체할 수 있다.
class LegacyObject {
fun oldMethod1() {
// ...
}
fun oldMethod2() {
// ...
}
}
class NewObject {
private val legacyObject = LegacyObject()
fun newMethod1() {
// ...
}
fun oldMethod2() {
legacyObject.oldMethod2()
}
}최종적으로 NewObject로 모든 기능을 이전하면 LegacyObject는 삭제할 수 있다.
class NewObject {
fun newMethod1() {
// ...
}
fun newMethod2() {
// ...
}
}이런 방식으로 먼저 레거시 코드 일부를 새로운 코드로 교체한 후 안정화 기간이 지난 다음 대체된 레거시 코드를 제거하는 것을 반복하는 것이 스트랭글러 무화과 패턴이다.
메서드 전문화
메서드 전문화는 메서드의 일반화를 줄이고 더 특정한 목적을 가지도록 하는 것을 말한다. 보통 개발자는 공통적인 것을 발견하면 일반화하는 것이 본능이다. 하지만 그 본능을 거스르고 일부러 메서드를 나누는 것이 메서드 전문화이다. 다음 예제를 살펴보자.
// 일반화된 메서드
fun calculate(a: Int, b: Int, operator: String): Int {
return when (operator) {
"+" -> a + b
"-" -> a - b
"*" -> a * b
"/" -> a / b
else -> throw IllegalArgumentException("Unknown operator")
}
}
// 메서드 전문화
fun add(a: Int, b: Int): Int {
return a + b
}
fun subtract(a: Int, b: Int): Int {
return a - b
}
fun multiply(a: Int, b: Int): Int {
return a * b
}
fun divide(a: Int, b: Int): Int {
return a / b
}일반화하지 않은 만큼 관리 포인트가 늘어날 수 있다. 하지만 변경에 있어서는 더 안전하다. 일반화된 메서드는 변경에 취약하다.
중복 코드 작성하기
변화율이 높은 곳에선 일부러 중복 코드를 작성하는 것도 좋은 방법이다. 만약 중복 코드가 생길 수 있는 부분에 변경이 될 것이라는 확신이 생긴다면 중복 코드를 작성하는 것이 좋다. 즉, 개발자의 경험과 직관에 따라 선택할 수 있다. 다만, 개발자의 본능을 매우 거스르는 일이므로 잘 떠올리기 어려울 수 있다. 따라서 변화율을 생각하며 코딩하는 것이 중요하다.
변화율 기록하기
변화율이 높을 것 같은 코드엔 주석을 통해 기록하는 것이 좋다. 단순히 한 줄 주석이라도 변화에 가능성이 있다면 메모해두는 것이 좋다. 이는 동료 개발자를 배려하는 것이기도 하며 나중에 코드를 다시 볼 때 도움이 된다.
마치며
이 글을 읽고나면 이미 있는 것을 잘 섞은 것 아닌가?라는 생각을 할 수 있다. 동의하지만 코드를 바라보는 관점이 다르다. 파괴가 빈번하게 발생하지 않는다면 이 글에서 설명한 방법론은 적합하지 않을 수 있다. 이 글은 다음으로 나아가기 위한 한 가지 제안이며 다른 형태로 발전할 수 있다.
이 글에서 가장 하고 싶은 말은 파괴 지향 개발이 좋으니 이를 사용해야 한다는 것이 아닌 기존의 틀을 깨고 끊임없이 무엇이 좋은가를 생각하자는 것이다. 그리고 만약 좋은 방법이 떠오른다면 생각을 정리하여 공유해보자. 누군가는 그 생각을 통해 더 나은 방법을 찾을 수 있을 것이다. 그런 관점에서 만약 자신이 최근 ‘파괴’한 코드가 있다면 댓글로 경험을 공유 해보자. 많은 사람들에게 큰 도움이 될 것이다.








