
미래 학자이자 SF 소설의 거장 아서 C. 클라크는 충분히 발달한 과학 기술은 마법과 구별할 수 없다라는 유명한 말을 남겼다. 이 말이 사실임을 증명하듯 현대 사회의 기술은 다양한 놀라움을 선사한다. 그 중에서도 Shazam이나 Soundhound와 같은 음악 검색 앱을 사용할 때 필자는 항상 마법을 쓰는 것 같은 기분을 느낀다.

음악 검색 앱은 대체 어떤 원리로 우리에게 놀라움을 선사할까? 이런 궁금증이 멈추지 않아 이번 기회에 음악 검색 알고리즘에 대해 알아보았고 생각보다 복잡하지 않아 이를 구현해보기로 결정했다. 이번 글에서는 음악 검색 시스템을 만들기 위한 알고리즘과 구현 방법에 대해 알아보겠다.
시스템 살펴보기
우선 음악 검색 시스템을 구현하기 위해선 몇 가지 신호 처리에 대한 지식과 알고리즘을 알아야 한다. 그러나 일단 배경 지식을 자세히 알아보기 전에 어떤 방식으로 음악 검색 시스템이 동작하는지 간단하게 알아보자.
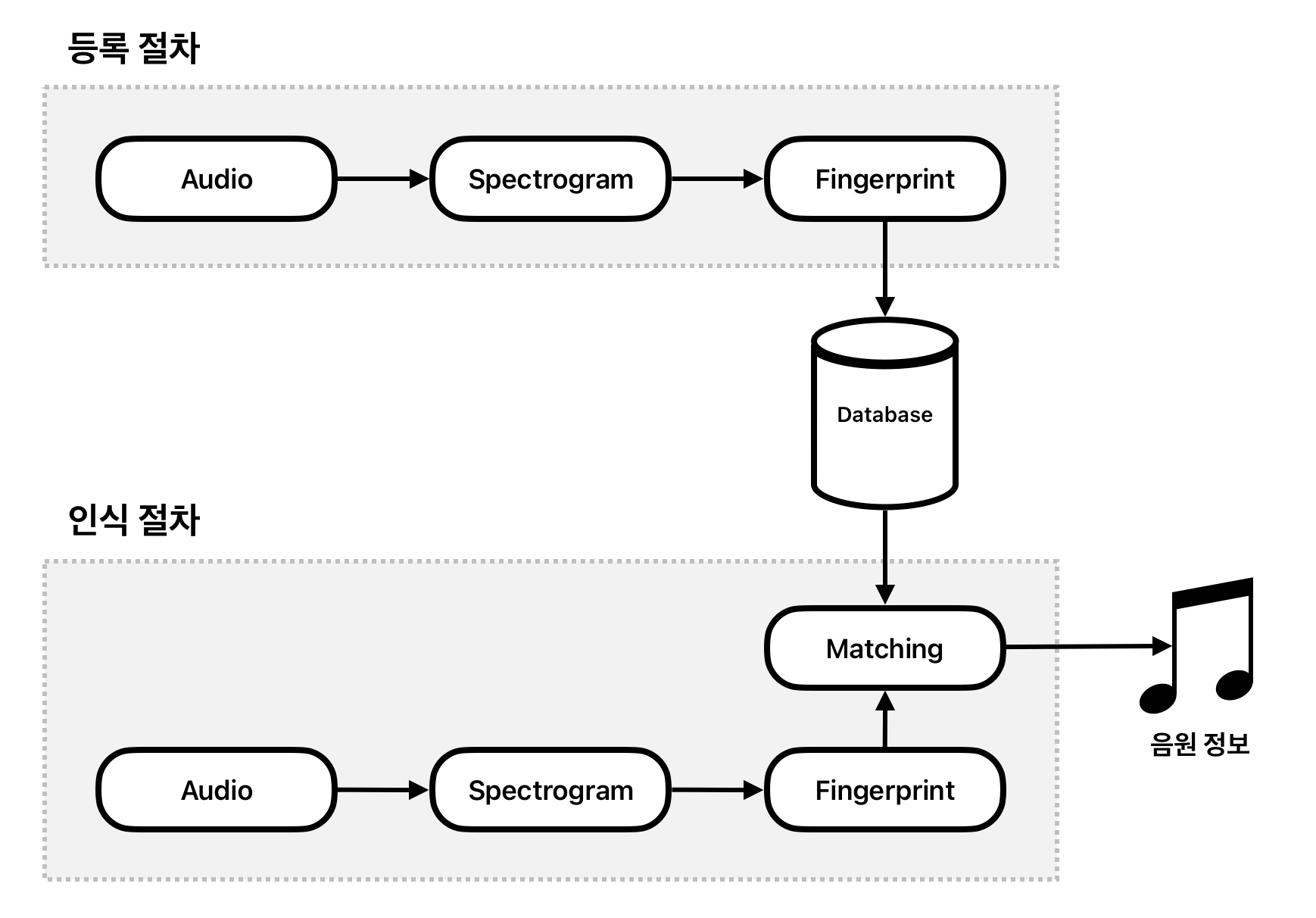
음악 검색 시스템은 크게 두 가지로 나눌 수 있다. 하나는 등록 절차로 이미 존재하는 음원을 소리 지문(Audio Fingerprint)이라는 것으로 만들어 데이터베이스에 저장하는 것이다. 여기서 말하는 소리 지문이란 음원에 대한 소리 정보를 해싱한 것으로 음원에서 추출한 스펙트로그램(Spectrogram)을 통해 만들 수 있다.
나머지 하나는 검색 절차로 입력받은 음원을 소리 지문으로 만들어 데이터베이스에 저장된 소리 지문과 대조하여 가장 유사한 음원을 찾아내는 것이다. 이 절차에서 대조하는 부분을 제외하면 등록 절차와 동일한 알고리즘을 사용한다. 따라서 음원에서 소리 지문 생성 알고리즘만 구현하면 음악 검색 시스템 90%는 완성했다고 볼 수 있다.
그럼 다음으로 소리 지문 생성 알고리즘이 어떻게 동작하는지 조금 더 자세히 알아보자. 다음 도식은 알고리즘을 조금 더 구체적으로 나타낸 것이다.
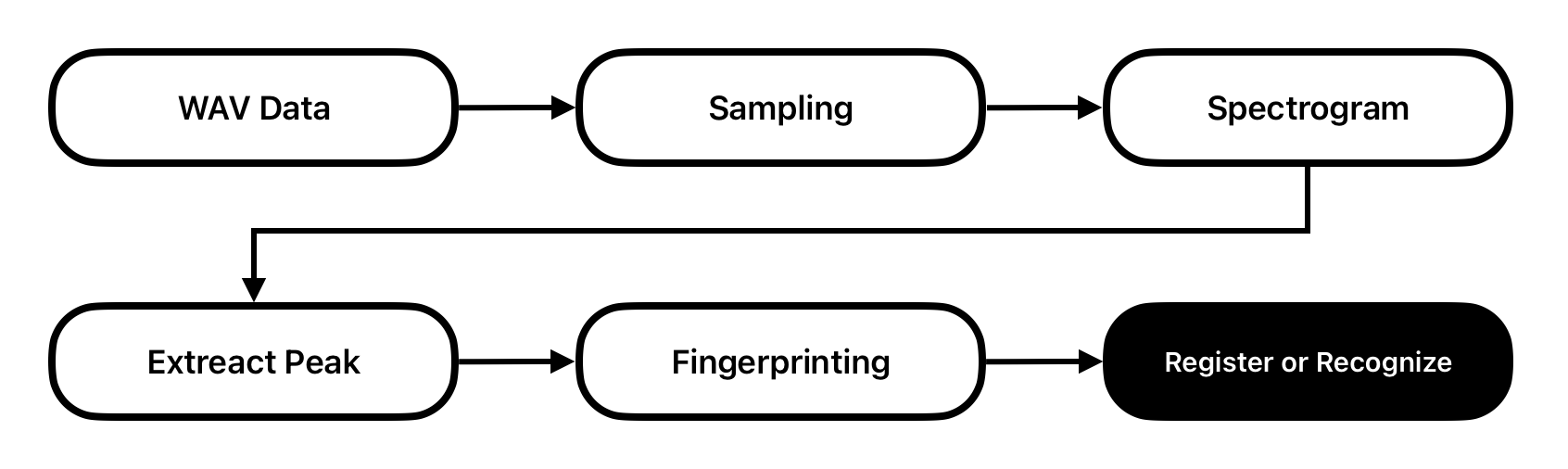
신호 처리 알고리즘에 대해 익숙하지 않다면 위 도식에서 사용된 용어가 생소할 수 있다. 지금 기억할 것은 위에 나온 용어를 이해하고 실제로 구현할 수 있다면 음악 검색 시스템을 만들 수 있다는 것이다.
배경 지식
이제 필요한 배경 지식을 하나씩 알아보자. 지금부터 앞서 언급한 샘플링(Sampling), 스펙트로그램(Spectrogram), 피크(Peak), 소리 지문(Audio Fingerprint)를 포함하여 관련된 지식을 익혀볼 것이다.
왜 WAV 파일인가?
음악 검색 시스템을 구현하기 위해선 변형되지 않은 음원을 사용해야 한다. 따라서 MP3, AAC, OGG 등의 손실 압축된 음원은 사용할 수 없다. 반면 WAV 파일은 비압축 PCM1 형식이기 때문에 변형되지 않은 원본 음원을 사용할 수 있다.
그래서 알고리즘 중 생략된 부분이 있다면 음원을 WAV로 변환하는 부분이다. 이 부분은 간단하게 FFmpeg를 사용하면 WAV로 변환할 수 있다.
ffmpeg -i input.mp3 -acodec pcm_s16le -ac 1 -ar 44100 output.wav한 가지 중요한 것은 채널 수와 샘플링 주파수를 맞추는 것이다. 채널(-ac)을 1로 설정하면 모노2로 변환하고 샘플링 주파수(-ar)를 44100으로 설정하면 1초당 44100개의 샘플링을 하게 된다.
여기서는 간단히 쉘에서 명령어를 실행하여 변환했지만 프로그램에서 사용할 때는 FFmpeg 라이브러리를 사용하여 처리하면 된다.
샘플링(Sampling)
앞서 샘플링 주파수를 언급했는데 샘플링이란 아날로그 신호를 디지털 신호로 변환하는 과정을 말한다. 아날로그 신호는 연속적인 값이지만 디지털 신호는 이산적인 값이다. 따라서 아날로그 신호를 디지털 신호로 변환하기 위해 일정한 시간 간격으로 샘플링하여 디지털 신호로 변환한다. 샘플링 주파수란 1초 동안 샘플링하는 횟수를 말한다. 이 횟수가 높을수록 원본 신호를 정확하게 표현할 수 있다.
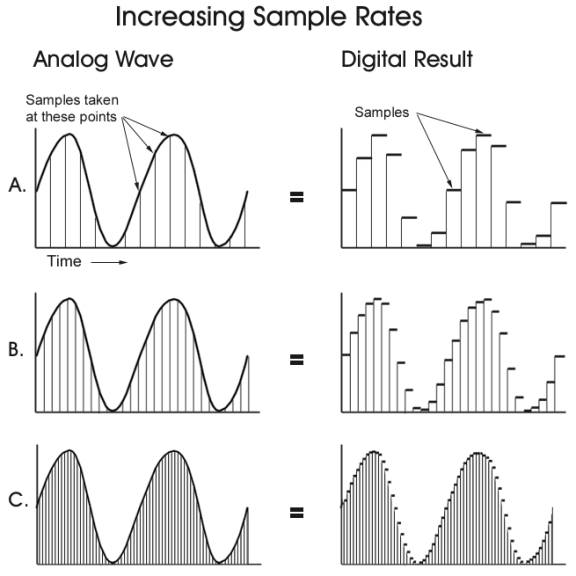
소리 지문을 만들기 위해서는 후술할 스펙트로그램이 필요하다. 이 스펙트로그램을 만들기 위해서는 샘플링된 데이터가 필요하고 이 데이터는 WAV 파일 바이트로부터 얻을 수 있다. 이 때문에 비압축 PCM 형식인 WAV 파일을 사용하는 것이다.
스펙트로그램(Spectrogram)
스펙트로그램은 시간에 따른 진폭과 주파수 변화를 시각화한 그래프이다. 이 말이 조금 어렵게 느껴질 수 있는데 오디오 프로그램에서 간혹 볼 수 있는 그래프같은 그림이 이 스펙트로그램을 기반으로 파형만을 이용해 만들어진 것이다.
파형은 시간과 진폭으로 이루어져 있다. 위 그림으로 치면 가로 축이 시간, 세로 축이 진폭이다. 이를 통해 시간에 따른 소리의 세기 변화를 알 수 있다. 여기서 스펙트로그램은 파형 뿐만 아니라 스펙트럼도 함께 표현한다.
스펙트럼은 주파수 영역에서의 세기를 나타내는 그래프로 가로 축이 주파수, 세로 축이 진폭에 해당한다. 다음 그림은 실제 스펙트로그램이다.

스펙트로그램은 가로 축(x축)이 시간, 세로 축(y축)이 주파수, 색상(z축)이 진폭을 나타낸다. 이를 통해 시간에 따른 진폭과 주파수의 세기 변화를 알 수 있다. 스펙트로그램은 소리 지문을 만들기 위한 중요한 데이터이다. 스펙트로그램은 FFT(Fast Fourier Transform) 알고리즘을 사용하여 만들 수 있다. 참고로 음악 검색을 위해서는 데이터만 필요하기 때문에 실제 시각화를 할 필요는 없다.
푸리에 변환(Fourier Transform)
앞서 스펙트로그램을 만들기 위해서는 FFT 알고리즘이 필요하다고 했다. 우선 맨 앞 Fast를 때고 푸리에 변환(Fourier Transform)이 무엇인지 알아보자.
푸리에 변환은 소리를 주파수 영역으로 변환하는 방법이다. 조금 더 쉽게 설명하자면 소리에서 어떤 주파수가 있는지 알아내는 것이 가능하다. 예를 들어, 20Hz 사인파 소리를 푸리에 변환하면 20Hz의 세기가 1이고 나머지는 0이 된다. 만약 20Hz와 40Hz 사인파 소리가 섞여 있다면 20Hz와 40Hz의 세기가 1이고 나머지는 0이 된다. 좀 더 복잡한 소리도 마찬가지로 주파수 영역으로 변환할 수 있다. 앞서 샘플링된 데이터를 만들었다면 이 데이터를 푸리에 변환하여 주파수 영역으로 변환할 수 있다.

앞서 만든 시간을 구간으로 나눠서 만든 샘플링 데이터를 푸리에 변환하면 시간의 흐름에 따른 주파수 진폭을 알 수 있다. 그리고 이를 통해 스펙트로그램을 만들 수 있다.
음악은 여러 주파수의 합으로 이루어져 있기 때문에 이 주파수가 노래를 고유하게 만들며 식별할 수 있게 한다. 따라서 푸리에 변환을 통해 만들어낸 스펙트로그램이 음악 검색 시스템에서 가장 중요하다고 볼 수 있다.
피크(Peak)
피크는 스펙트로그램에서 주파수 영역에서의 세기가 높은 부분을 말한다. 스펙트로그램 그림에서 보자면 피크는 색상이 짙은 부분을 말한다. 피크는 (시간, 주파수) 쌍으로 이루어져 있으며 정확도를 위해 각종 노이즈를 필터링하고 성능을 위해 적절한 시간 간격을 두어야 한다. 피크를 추출하는 이유는 두 가지다.
- 피크를 찾아 추출하면 효과적으로 스펙트로그램을 압축할 수 있기 때문이다.
- 추출한 피크를 통해 소리 지문을 만들기 위함이다.
사실 스펙트로그램 데이터 자체를 소리 지문으로 사용할 수도 있지만 이는 너무 데이터가 많아 비효율적이다. 피크를 추출하면 더 효율적으로 적은 데이터로 소리 지문을 만들 수 있다. 그래서 피크를 추출하는 것은 성능을 위해 필요한 작업이다.
소리 지문(Audio Fingerprint)
추출한 피크를 해싱하면 소리 지문이 된다. 해싱을 어떻게 할지는 구현 방법에 따라 다르지만 피크 수가 적지 않으므로 해싱 성능을 고려해야 한다. 이렇게 만들어진 소리 지문은 데이터베이스에 저장하여 음악을 식별할 때 사용한다.
구현
앞서 알아본 배경 지식을 바탕으로 실제 음악 검색 시스템을 구현해보자. 음악 검색 시스템을 만들기 위한 과정은 다음과 같다.
- WAV 파일을 읽어 샘플링 데이터를 만든다.
- 샘플링 데이터를 푸리에 변환하여 스펙트로그램을 만든다.
- 스펙트로그램에서 시간대 별로 피크를 추출한다.
- 추출한 여러 피크를 해싱하여 소리 지문을 만든다.
- 소리 지문을 데이터베이스에 저장하거나 검색하여 가장 유사한 음원을 찾는다.
실제 구현할 때는 위 과정에서 최적화와 정확도를 위해 여러 방법을 사용해야 한다. 이 부분이 각 음악 검색 서비스의 핵심이라고 볼 수 있다.
그럼 이제 동작하는 코드를 작성해보자. 여기서 WAV로 변환하는 것은 생략할 것이며 간단하게 구현하기 위해 데이터베이스도 이용하지 않을 것이다. 그리고 언어는 Rust를 사용할 것이다. 성능 같은 이유는 아니고 이후 WASM으로 빌드하여 웹에서 동작시키기 위함이다.
알고리즘 절차
먼저 앞서 설명한 알고리즘 절차를 코드로 작성해보자.
// 소리 지문을 저장할 전역 변수
// DB를 사용하지 않을 것이다
static mut MUSIC_FINGERPRINTS: Vec<(String, Vec<u64>)> = Vec::new();
pub fn register(name: String, data: Vec<u8>) {
// 1. WAV 데이터에서 샘플링 데이터를 만든다
let samples = bytes_to_samples(data);
// 2. 샘플링 데이터로 스펙트로그램을 만든다
let spectrogram = create_spectrogram(samples);
// 3. 스펙트로그램에서 피크를 추출한다
let peaks = extract_peaks(spectrogram);
// 4. 피크로 소리 지문을 만든다
let fingerprints = create_fingerprints(peaks);
// 5. 소리 지문을 메모리에 저장한다
unsafe {
MUSIC_FINGERPRINTS.push((name, fingerprints));
}
}
pub fn search(data: Vec<u8>) -> String {
// 1. WAV 데이터에서 샘플링 데이터를 만든다
let samples = bytes_to_samples(data);
// 2. 샘플링 데이터로 스펙트로그램을 만든다
let spectrogram = create_spectrogram(samples);
// 3. 스펙트로그램에서 피크를 추출한다
let peaks = extract_peaks(spectrogram);
// 4. 피크로 소리 지문을 만든다
let fingerprints = create_fingerprints(peaks);
// 5. 소리 지문을 검색하여 가장 유사한 음원을 찾아 반환한다
unsafe {
search_fingerprints(MUSIC_FINGERPRINTS.clone(), fingerprints)
}
}위 코드는 앞서 설명한 알고리즘 절차를 그대로 코드로 옮긴 것이다. 실제로 동작시키기 위해선 각 함수를 구현해야 한다.
샘플링 데이터 만들기
먼저 WAV 파일 데이터를 읽어 샘플링 데이터를 만들어보자.
pub fn bytes_to_samples(data: Vec<u8>) -> Vec<f32> {
if data.len() % 2 != 0 {
panic!("Invalid WAV data");
}
let mut samples = Vec::new();
for i in 0..data.len() / 2 {
let sample = i16::from_le_bytes([data[i * 2], data[i * 2 + 1]]);
samples.push(sample as f32 / i16::MAX as f32); // sample / 32768.0
}
samples
}위 코드는 WAV 파일 데이터를 읽어 샘플링 데이터로 변환하는 함수이다. 우선 규칙 상 WAV 파일 바이트의 길이는 2의 배수여야 하므로 이를 체크하여 올바른 데이터인지 확인 할 수 있다.
그리고 WAV는 16비트로 인코딩되어 있기 때문에 2바이트씩 읽어 i16로 변환한 후 f32로 변환하여 -1.0 ~ 1.0 사이의 값으로 정규화한다. 즉, 2바이트 단위로 샘플링 데이터를 만들었다는 뜻이다.
스펙트로그램 만들기
다음으로 추출한 샘플링 데이터로 스펙트로그램을 만들어보자. 여기서는 FFT 알고리즘을 사용하기 위해 RustFFT 라이브러리를 사용할 것이다.
use rustfft::{FftPlanner, num_complex::Complex};
use std::f32::consts::PI;
/// 해밍 윈도우를 적용해 각 프레임을 생성
fn hamming_window(size: usize) -> Vec<f32> {
(0..size).map(|i| 0.54 - 0.46 * ((2.0 * PI * i as f32) / (size as f32 - 1.0)).cos()).collect()
}
/// 간단한 저역 통과 필터 적용
fn low_pass_filter(samples: &[f32], max_freq: f32, sample_rate: f32) -> Vec<f32> {
samples.iter().map(|&s| if s < max_freq / sample_rate { s } else { 0.0 }).collect()
}
/// 다운샘플링을 수행하여 샘플 수 줄임
fn downsample(input: &[f32], original_sample_rate: usize, target_sample_rate: usize) -> Vec<f32> {
let ratio = original_sample_rate / target_sample_rate;
input.iter().step_by(ratio).copied().collect()
}
/// 스펙트로그램 생성 함수
pub fn create_spectrogram(samples: Vec<f32>) -> Vec<Vec<f32>> {
let sample_rate: usize = 44100;
let max_freq: f32 = 5000.0;
let freq_bin_size: usize = 1024;
let hop_size: usize = 512;
let dsp_ratio: usize = 4;
// 저역 통과 필터 적용 및 다운샘플링
let filtered_samples = low_pass_filter(&samples, max_freq, sample_rate as f32);
let downsampled_samples = downsample(&filtered_samples, sample_rate, sample_rate / dsp_ratio);
let num_windows = downsampled_samples.len() / (freq_bin_size - hop_size);
let mut spectrogram = Vec::with_capacity(num_windows);
// 해밍 윈도우 생성
let window = hamming_window(freq_bin_size);
// FFT 설정
let mut planner = FftPlanner::new();
let fft = planner.plan_fft_forward(freq_bin_size);
for i in 0..num_windows {
let start = i * hop_size;
let end = start + freq_bin_size;
let mut bin = vec![Complex::new(0.0, 0.0); freq_bin_size];
// 윈도우링 적용
for j in 0..freq_bin_size {
if start + j < downsampled_samples.len() {
bin[j] = Complex::new(downsampled_samples[start + j] * window[j], 0.0);
}
}
// FFT 수행
fft.process(&mut bin);
// 스펙트럼 강도 계산 후 저장
let spectrum_magnitudes: Vec<f32> = bin.iter().map(|c| c.norm()).collect();
spectrogram.push(spectrum_magnitudes);
}
spectrogram
}위 코드는 샘플링 데이터를 받아 스펙트로그램을 만드는 함수이다. 먼저 노이즈와 사람에게 의미없는 고주파 주파수를 제거하기 위해 저역 통과 필터(Low-pass filter)를 적용하여 원하는 주파수 이상의 데이터를 제거한다. 이를 통해 스펙트로그램을 만드는 소요 시간을 줄일 수 있다.
그리고 이어서 FFT를 수행하기 위해 다운샘플링을 수행하여 샘플 수를 줄인다. 여기서는 44100 단위로 샘플링된 데이터를 11025 단위로 다운샘플링한다.
이어서 해밍 윈도우를 적용하여 각 프레임을 생성하고 FFT를 수행하여 스펙트럼을 계산한다. 해밍 윈도우는 FFT를 수행하기 전에 적용하여 주파수 영역에서의 세기를 계산할 수 있게 한다.
이 절차를 진행하고 나면 스펙트로그램이 생성된다.
피크 추출하기
이제 앞서 생성된 스펙트로그램에서 피크를 추출해보자.
/// 스펙트로그램을 분석하여 주파수 대역에서 주요 피크를 추출하는 함수
pub fn extract_peaks(spectrogram: Vec<Vec<f32>>, audio_duration: f32) -> Vec<(usize, usize)> {
if spectrogram.is_empty() {
return Vec::new();
}
let bands = vec![(0, 10), (10, 20), (20, 40), (40, 80), (80, 160), (160, 512)];
let bin_duration = audio_duration / spectrogram.len() as f32;
let mut peaks = Vec::new();
for (bin_idx, bin) in spectrogram.iter().enumerate() {
let mut max_mags = Vec::new();
let mut max_freqs = Vec::new();
let mut freq_indices = Vec::new();
for (min, max) in &bands {
let mut max_mag = 0.0;
let mut max_freq_idx = *min;
for freq_idx in *min..*max {
if freq_idx < bin.len() {
let magnitude = bin[freq_idx];
if magnitude > max_mag {
max_mag = magnitude;
max_freq_idx = freq_idx;
}
}
}
if max_mag > 0.0 {
max_mags.push(max_mag);
max_freqs.push(Complex::new(bin[max_freq_idx], 0.0));
freq_indices.push(max_freq_idx as f32);
}
}
// 평균 진폭 계산
let avg_magnitude = max_mags.iter().sum::<f32>() / max_mags.len() as f32;
// 평균보다 큰 피크만 추출하여 추가
for (i, &value) in max_mags.iter().enumerate() {
if value > avg_magnitude {
let peak_time_in_bin = freq_indices[i] * bin_duration / bin.len() as f32;
let peak_time_index = (bin_idx as f32 * bin_duration + peak_time_in_bin) as usize;
// (시간 인덱스, 주파수 인덱스) 튜플을 추가
peaks.push((peak_time_index, freq_indices[i] as usize));
}
}
}
peaks
}먼저 효율을 위해 주파수 대역을 나눌 것이다. 여기서는 0 ~ 10, 10 ~ 20, 20 ~ 40, 40 ~ 80, 80 ~ 160, 160 ~ 512로 나눌 것이다. 이렇게 나누는 이유는 주파수 대역을 나누어 피크를 추출하면 더 정확하게 추출할 수 있기 때문이다.
그리고나서 각 주파수 대역에서 가장 큰 피크를 추출하여 평균 진폭을 계산한다. 이 평균 진폭보다 큰 피크만 추출하여 반환한다.
소리 지문 만들기
마지막으로 추출한 피크를 해싱하여 소리 지문을 만들어보자.
pub fn create_fingerprints(peaks: Vec<(usize, usize)>) -> Vec<u64> {
let mut fingerprints = Vec::new();
let target_zone_size = 3;
for i in 0..peaks.len() {
for j in i + 1..peaks.len() {
if j <= i + target_zone_size {
let anchor = peaks[i];
let target = peaks[j];
let address = create_address(anchor, target);
let anchor_time_ms = (anchor.0 as f32 * 1000.0) as u32;
fingerprints.push((address as u64) << 32 | anchor_time_ms as u64);
}
}
}
fingerprints
}
pub fn create_address(anchor: (usize, usize), target: (usize, usize)) -> u32 {
let anchor_freq = anchor.1;
let target_freq = target.1;
let delta_ms = ((target.0 - anchor.0) as f32 * 1000.0) as u32;
(anchor_freq as u32) << 23 | (target_freq as u32) << 14 | delta_ms
}위 코드는 추출한 피크를 해싱하여 소리 지문을 만드는 함수이다. 여기서는 피크를 3개씩 묶어 해싱하여 소리 지문을 만들었다. 이렇게 해싱하면 소리 지문을 더 효율적으로 만들 수 있다.
음악 검색 함수 만들기
이제 구현한 함수를 이용하여 음원을 검색해보자.
pub fn search_fingerprints(registered: Vec<(String, Vec<u64>)>, fingerprints: Vec<u64>) -> String {
let mut score_map: HashMap<usize, usize> = HashMap::new();
// 저장된 각 노래와 비교하여 일치도 계산
for (i, (_, existing_fingerprints)) in registered.iter().enumerate() {
for fingerprint in &fingerprints {
if existing_fingerprints.contains(fingerprint) {
*score_map.entry(i).or_insert(0) += 1;
}
}
}
// 최고 점수를 가진 항목 찾기
let (best_index, best_score) = score_map.iter().max_by_key(|&(_, count)| count).map(|(&i, &count)| (i, count)).unwrap_or((0, 0));
// 일정 임계값 이상일 때만 결과 반환, 그렇지 않으면 "Not found" 반환
const MIN_SCORE_THRESHOLD: usize = 5;
if best_score >= MIN_SCORE_THRESHOLD {
json!({
"songName": registered[best_index].0.clone(),
"score": best_score
}).to_string()
} else {
json!({
"songName": "Not found",
"score": 0
}).to_string()
}
}위 코드는 저장된 소리 지문과 입력받은 소리 지문을 비교하여 가장 유사한 음원을 찾는 함수이다. 이 함수는 저장된 소리 지문과 입력받은 소리 지문을 비교하여 일치하는 소리 지문이 있을 때마다 점수를 증가시킨다. 그리고 가장 높은 점수를 가진 음원을 찾아 반환한다.
녹음해서 검색하기
마지막으로 실제로 녹음해서 검색할 수 있게 예제 코드를 작성해보자. 이 부분은 HTML과 JS를 사용하여 크롬 브라우저에서 실행 가능하도록 구현할 것이다.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Music Search</title>
</head>
<body>
<h1>Music Search</h1>
<button id="recordButton">Record and Search</button>
<div id="output"></div>
<script type="module" src="index.js" defer></script>
</body>
</html>우선 간단하게 HTML을 만들었다. 이제 JS 코드를 작성해보자.
import init, { register, search } from "./ringabell.js";
import { FFmpeg } from "./ffmpeg/ffmpeg/index.js";
import { toBlobURL } from "./ffmpeg/util/index.js";
// FFmpeg WASM 라이브러리 로드
async function loadFFmpeg() {
const baseURL = "https://unpkg.com/@ffmpeg/core@0.12.6/dist/umd";
const ffmpeg = new FFmpeg();
await ffmpeg.load({
coreURL: await toBlobURL("/ffmpeg/core/ffmpeg-core.js", "text/javascript"),
wasmURL: await toBlobURL(
"/ffmpeg/core/ffmpeg-core.wasm",
"application/wasm"
),
});
return ffmpeg;
}
async function main() {
await init(); // Wasm 모듈 초기화
const recordButton = document.getElementById("recordButton");
const output = document.getElementById("output");
recordButton.addEventListener("click", async () => {
output.textContent = "Listening...";
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
const audioContext = new AudioContext();
const mediaRecorder = new MediaRecorder(stream);
const audioChunks = [];
// 녹음 데이터 수집
mediaRecorder.ondataavailable = (event) => {
audioChunks.push(event.data);
};
// 녹음 종료 후 처리
mediaRecorder.onstop = async () => {
const audioBlob = new Blob(audioChunks, { type: "audio/webm" });
const audioBytes = new Uint8Array(await audioBlob.arrayBuffer());
// 크로미움은 녹음된 오디오를 webm으로 저장하기 때문에 wav로 변환
await ffmpeg.writeFile("input.webm", audioBytes);
await ffmpeg.exec([
"-i",
"input.webm",
"-acodec",
"pcm_s16le",
"-ac",
"1",
"-ar",
"44100",
"output.wav",
]);
const data = await ffmpeg.readFile("output.wav");
// 결과 데이터 파싱
const result = JSON.parse(await search(data));
// 스코어가 0이라면 "Not found" 출력
if (result.score === 0) {
output.textContent = "Not found";
}
// 그렇지 않으면 검색 결과 출력
else {
output.textContent = `Search result: ${result.songName}`;
}
};
// 녹음 시작
mediaRecorder.start();
// 10초 후 녹음 종료
setTimeout(() => {
mediaRecorder.stop();
output.textContent = "Processing...";
}, 10000);
});
}
main();위 코드에선 앞서 작성한 Rust 코드를 WASM으로 빌드하는 것과 ffmpeg.wasm을 이용하여 녹음된 오디오를 WAV로 변환하는 것을 어느정도 생략했다. 또한 음원을 등록하는 부분도 생략했다.
핵심 코드만 살펴보면 녹음 버튼을 누르면 10초간 녹음한 후 녹음된 오디오를 WAV로 변환하여 검색하는 것이다. 검색 결과가 있으면 결과를 출력하고 없으면 “Not found”를 출력한다.
실제 테스트는 링크에서 가능하다. 접속하면 곡을 등록하는 것도 가능하다. Record and Search 버튼을 클릭하면 녹음이 시작되며 10초간 녹음한 후 검색 결과를 확인할 수 있다. 만약 사용할 만한 곡이 없다면 유튜브 오디오 라이브러리에서 다운로드 받아 테스트할 수 있다.
마치며
이번 글에서는 음악 검색 시스템을 만들기 위한 알고리즘과 구현 방법에 대해 알아보았다. 이미 잘 작동하는 서비스도 많고 관련 API도 많지만 직접 구현해보는 것도 재미있는 경험이 될 것이다. 그리고 꼭 음악 검색이 아니더라도 노래방 점수 계산이나 저작권 침해 검출 등 다양한 분야에 적용할 수 있을 것이라 생각한다. 앞으로 이러한 개발을 안할 것이라는 보장은 없으니 알아둬서 나쁠건 없다고 생각한다.
이 글에서 만든 음악 검색 시스템은 기본적인 기능만을 제공할 뿐이며 실제 서비스에 적용하기 위해서는 더 치밀한 알고리즘 개발이 필요하다. 다른 소리가 섞이거나 음악의 톤이 달라지는 경우, 리믹스 등의 경우에는 정확도가 떨어지고 이를 잘 처리하는 것이 기술력이라고 볼 수 있다.








